2026 is shaping up as another tough year for layoffs and hiring freezes, but it is more a continuation and restructuring phase than a completely new “mass bloodbath” like early 2023.
What is actually happening in 2025–2026
Tech layoffs re-accelerated through 2025, with over 100,000 tech workers cut and more than 200 tech companies reducing headcount globally.[economictimes]
Many of these 2025 cuts came from large players (Amazon, Intel, TCS, Google, Meta) shifting priorities, especially towards AI and away from older or lower‑margin lines.[tomshardware]
Early 2026 has already seen fresh rounds from firms like Meta (Reality Labs), Citigroup, and BlackRock, suggesting the 2025 pattern is carrying into this year.[business-standard]
Why leaders expect more cuts in 2026
Surveys of executives show a clear bias towards staying lean: roughly two‑thirds of CEOs say they plan to either cut or hold headcount flat in 2026 rather than grow it.[saastr]
One 2025 survey of 1,000 US business leaders found half had already pulled back on hiring, nearly 40% had done layoffs in 2025, and a majority expected further layoffs to be likely in 2026.[hrdive]
Another survey of hiring managers reported that more than half expect layoffs in 2026 and see AI as a top driver of those cuts, especially for white‑collar roles.[informationweek]
AI, “invisible unemployment,” and who is most exposed
A growing chunk of the pain is “invisible”: roles quietly eliminated via attrition, aggressive performance management, relocation/RTO pressure, and not backfilling departures, so the headline layoff numbers understate the chill.[saastr]
Economists and industry observers describe 2026 as a “Great Freeze”: fewer new openings, more restructuring, and companies using AI plus process changes to do the same work with fewer people.[linkedin]
High‑salary staff without strong AI or automation skills, recently hired employees, and some entry‑level roles are viewed by executives as the highest‑risk groups for future cuts.[hrdive]
How this likely feels in tech and AI infra
For people in tech, 2026 is likely to feel like a grinding reset: fewer net new roles, more churn between companies, and continued pressure on anything tied purely to speculative AI or overbuilt infra.[info.siteselectiongroup]
At the same time, companies are heavily investing in a smaller core of people who can build, operate, and productize AI and automation, including infra and observability talent, rather than cutting across the board.[finalroundai]
Practical implications for you
Treat 2026 as a year to be defensive:
Make sure your current role is visibly tied to cost savings, reliability, or revenue, not just “innovation theatre”.[perplexity]
Double down on AI‑adjacent skills (MLOps, GPU/AI infra, automation with AI copilots) so you’re in the “kept and retrained” cohort rather than the expendable one.[tomshardware]
If you’re in AI/data‑center/infra, the risk is more about over‑concentration in a fragile employer or product line than the whole category disappearing; diversified or sovereign‑backed infra tends to ride out the cycle better.[perplexity]
In 2025, economic analysts and sociologists, most notably in a widely discussed analysis by The Economist, have identified Generation X (born 1965–1980) as the “real loser generation” due to a unique convergence of financial and social setbacks.
The primary reasons Gen X is characterized this way include:
Wealth Lag: Despite being at their peak earning years, Gen X has significantly less wealth than previous generations at the same age. For example, 2025 data shows that Millennials at age 31 have roughly double the wealth that the average Gen Xer had at that same point in their life.
The “Sandwich” Squeeze: Gen X is currently under intense pressure as the “Sandwich Generation,” simultaneously caring for aging parents and supporting their own children. Over 54% of Americans in their 40s are now balancing these dual caregiving roles.
Poor Market Timing: This cohort faced a “lost decade” in the stock market during the 2000s, precisely when they should have been building wealth. They entered the workforce during recessions and were hit by the 2008 financial crisis just as they were entering their prime career stages.
Invisible at Work: Many Gen Xers report feeling invisible in a corporate landscape that increasingly values younger “tech-native” talent (Millennials/Gen Z) or retains aging Baby Boomer leaders. Some corporations are reportedly “skipping over” Gen X for C-suite promotions in favor of younger leaders.
Retirement Anxiety: Unlike Boomers who often had stable pensions, Gen X must rely on volatile 401(k) plans and a shaky Social Security outlook. Nearly 60% of Gen Xers now expect to work past age 65.
Cultural Neglect: Often called the “latchkey kids” or the “forgotten generation,” Gen X is largely ignored in the cultural “generational wars” between Boomers and Millennials. They lack the media attention and political influence of the larger cohorts that flank them.
We have some wins
Gen X has been pivotal in education, technology, leadership, and cultural change, often acting as the **bridge** between older and younger cohorts.
Tech and innovation advantages
– Gen X was the first cohort to grow up alongside personal computers, the internet, and mobile phones, giving them a rare comfort with both analog and digital worlds.
– Many Gen X entrepreneurs lead in adopting new technologies and using them to create innovative business models, especially in tech, finance, and e‑commerce.
Educational and career gains
– Gen X was the first generation to face a labor market that effectively required postsecondary education for good jobs and responded with higher college attainment than Baby Boomers at similar ages.
– College‑educated Gen Xers typically enjoy higher incomes and greater wealth than less‑educated peers, showing that many in this cohort successfully leveraged education into upward mobility.
Leadership and workplace strengths
– Gen X workers are now heavily represented in senior and executive roles, bringing deep institutional knowledge, strong work ethic, and problem‑solving skills to leadership.
– Employers see Gen X as especially adaptable and resilient, having navigated repeated economic and technological shifts while still driving transformation in their organizations.
Bridge between generations
– Positioned between Boomers and Millennials, Gen X is widely described as a mediator generation that understands traditional hierarchies and newer, more fluid work cultures, smoothing communication across age groups.
– In workplaces, Gen X frequently acts as the connector between colleagues who struggle with digital tools and those who are “always online,” helping teams stay cohesive and productive.
Cultural and lifestyle benefits
– Gen X helped define late‑20th‑century and early‑internet culture: from alternative music and independent film to early online communities and gaming, leaving a lasting cultural footprint.
– Compared with older cohorts, many Gen Xers place a high value on work‑life balance and flexibility and have been key drivers in normalizing remote work, flexible hours, and more autonomous, less hierarchical work styles.
Conclusion
Yep, balancing things up, I can conclude we are the losers…
AI refers to machines performing tasks that typically require human intelligence. AGI is AI with general, human‑level cognitive abilities across a wide range of tasks. ASI is a hypothetical AI that surpasses human intelligence in virtually all domains.
Overview
AI or ANI (Artificial Narrow Intelligence): specialized AI that excels at specific tasks (e.g., image recognition, playing chess, language translation). It’s the most common form in use today.
AGI (Artificial General Intelligence): systems with broad, human‑level capabilities—understanding, learning, reasoning, and applying knowledge across many domains.
ASI (Artificial Superintelligence): a level of intelligence that greatly exceeds human capabilities in all areas.
Scope of tasks
ANI: narrow scope, task-specific
AGI: wide, adaptable reasoning across domains
ASI: superior performance in everything, including creativity and problem‑solving
Learning and adaptability:
ANI: learns within fixed parameters and datasets
AGI: can learn from diverse experiences and transfer knowledge
ASI: continuously self‑improves beyond human constraints
Current state and timelines
ANI is ubiquitous today, powering search, assistants, recommendations, and more.
AGI remains aspirational; estimates vary widely among researchers, with no consensus on when or even if it will be achieved.
ASI is speculative science fiction at present; most experts agree it would require breakthroughs beyond AGI.
Potential implications
Economic and labor impacts: automation of complex tasks could shift job roles and demand new skills.
Safety and governance: AGI/ASI would raise significant ethical, safety, and governance questions, including alignment with human values.
Research and science: AGI could accelerate discovery across fields, from medicine to physics.
Common misconceptions
AGI does not imply immediate, conscious machines with emotions; it implies broad cognitive capabilities.
ASI does not mean instant, uncontrollable intelligent beings; it depends on many speculative breakthroughs and safety frameworks.
Summary
ANI: specialized AI for specific tasks
AGI: human‑level general intelligence across tasks
ASI: intelligence far surpassing human capabilities
How do AGI and ASI differ in capabilities
AGI is defined as AI that can match human-level intelligence across many domains, while ASI is a hypothetical future AI that would far surpass the best human minds in virtually all areas of cognition. Both are more capable than today’s narrow AI, but ASI adds superhuman scale, speed, and depth along with the ability to improve itself far beyond human limits.softbank+3
Core capability difference
AGI: Human-level performance on most intellectual tasks, including learning, reasoning, planning, and adapting across domains, similar to a broadly educated person.wikipedia+1
ASI: Superhuman performance in essentially every intellectual task, including science, strategy, creativity, and long-term planning, not just faster computation.moontechnolabs+2
In short, AGI aims to do what humans can do; ASI aims to do far more than humans can do, in both breadth and depth.netguru+1
Learning and self‑improvement
AGI: Can learn from diverse data and experiences, transfer knowledge between domains, and adapt to new tasks, but its self‑improvement is still constrained by design and human oversight.softbank+2
ASI: Typically defined as recursively self‑improving—able to redesign its own algorithms, generate its own training data, and continually increase its capabilities without direct human guidance.creolestudios+2
This recursive self‑improvement is a key reason ASI is often linked to the “intelligence explosion” or technological singularity.netguru+1
Scope and problem‑solving
AGI: Expected to handle any task a human knowledge worker could, from scientific research to teaching, software engineering, or policy analysis, with strong but roughly human‑comparable judgment.kanerika+2
ASI: Would solve problems beyond human comprehension, discover patterns humans cannot see, and generate new scientific theories or technologies at a pace and sophistication that humans could not match.moontechnolabs+2
Where AGI might collaborate with humans as a peer, ASI would function more like an extremely powerful, alien-level expert.
Table: AGI vs ASI capabilities
Aspect
AGI (General)
ASI (Superintelligence)
Intelligence level
Roughly human-level across many domains.wikipedia+2
Vastly beyond the best human experts in all domains.softbank+2
Learning style
Learns and generalizes across tasks like a human.softbank+2
Creates its own learning strategies and data; recursively self‑improving.softbank+1
Problem‑solving
Solves most tasks humans can, with high flexibility.moontechnolabs+1
Cracks problems humans cannot even fully specify or understand.softbank+2
Speed and scale
Similar cognitive range to humans, but faster on some tasks.moontechnolabs
Operates at machine speed on global, massive‑scale data streams.moontechnolabs+1
Novel discovery
Can assist and sometimes lead human‑level research.moontechnolabs+1
Drives radical breakthroughs in science, technology, and strategy autonomously.moontechnolabs+1
Self‑modification
Limited or controlled self‑improvement.softbank+1
Open‑ended self‑modification and optimization of its own code and goals (in many visions).softbank+2
Status today
AGI: Still not achieved; current systems are closer to advanced narrow or “weak” forms of generality, and AGI remains an aspirational research target.viso+2
ASI: Entirely speculative at present, dependent on first reaching robust AGI and then enabling powerful recursive self‑improvement.kanerika+2
If you want to go deeper, the next useful dimension is risk and governance differences: why AGI raises big alignment questions, and why ASI raises civilization‑level control questions.
What are real world uses of AGI today
There are no widely accepted, deployed AGI systems in the strict “human‑level general intelligence” sense today; what exists are advanced narrow or “proto‑AGI” models being used in many real‑world applications. Most concrete use cases branded as “AGI” are actually powerful generative or multimodal AI applied across multiple tasks rather than true general intelligence.sidetool+3
Important clarification
No consensus that AGI exists yet: Surveys and 2025 overviews still describe AGI as a future milestone that requires breakthroughs in general problem‑solving and knowledge transfer.kanerika+1
Marketing vs reality: Many articles and vendors use “AGI” aspirationally for advanced models, but technical write‑ups usually treat them as steps toward AGI, not fully general minds.techrevolt+2
So “real‑world uses of AGI” today are better described as uses of advanced AI that show some generality but remain below true AGI.
Advanced AI uses often framed as AGI‑like
Autonomous task agents in business: End‑to‑end agents can plan, call tools, and complete tasks such as drafting contracts, generating code, and running simple workflows with minimal oversight.cloud.google+1
Cross‑domain copilots: Enterprise copilots (e.g., Google’s Gemini‑based Workspace assistants) summarize mail, generate documents, analyze sheets, and answer questions over internal knowledge, acting as a general knowledge worker assistant within one organization.cloud.google
These systems show broader versatility than classic narrow AI but still lack robust, human‑level general understanding and autonomy.scientificamerican+1
Examples often cited as “AGI use cases”
Healthcare decision support: Systems like IBM’s Watson Health analyze patient records and large medical literature corpora to suggest treatment options and support oncology decisions, sometimes cited as early AGI‑style reasoning in a specialized domain.ibm+1
Industrial optimization and predictive maintenance: Large AI systems monitor sensor data, detect anomalies, and optimize complex production lines or logistics networks, adjusting schedules and predicting failures in near real time.ibm+1
These fit “powerful domain‑general within a vertical” more than “fully general intelligence.”
Multimodal “proto‑AGI” applications
Customer service and sales: Multimodal models that understand text, voice, and sometimes images are used for richer customer support, sentiment‑aware responses, and context‑aware recommendations.weforum+2
Knowledge and research assistance: Large models are used for legal analysis, financial modeling aid, and code generation, giving human experts faster access to cross‑domain information and draft reasoning.sidetool+1
Some commentators argue these systems are “chasing and occasionally catching” AGI capabilities in narrow slices, but they are not yet considered true AGI by most researchers.techrevolt+2
How to interpret “AGI in the real world” today
In research and journalism, “AGI use cases” usually mean: “Here’s what AGI would do in healthcare, manufacturing, logistics, etc.” rather than deployments of a confirmed AGI.kanerika+1
In industry and marketing, the term often labels very capable general‑purpose assistants or agents built on frontier generative models that are still narrow compared with human general intelligence.sidetool+2
If you want, the next step can be mapping specific “AGI‑like” patterns (tool‑using agents, long‑horizon planners, cross‑modal perception) to concrete systems you’re likely to encounter in enterprise or developer workflows.
What is the progress to ASI – how near are we?
Artificial superintelligence (ASI) does not exist today, and expert views on when or whether it will emerge vary enormously, from “possibly this century” to “not with current approaches, if ever.” The only honest summary is that progress is rapid toward stronger AI systems, but ASI remains speculative and timeline estimates are highly uncertain.theaireport+2
Where we are now
Current frontier models show impressive gains in coding, reasoning benchmarks, and multimodal tasks, and some can already write and improve their own software in constrained settings.scientificamerican+1
However, these systems still fail in robust general reasoning, long‑horizon planning, and reliable self‑improvement—capabilities most definitions of AGI or ASI would require.hai.stanford+1
So the field is in a phase of “advanced but brittle” systems, not in sight of true superintelligence.
Expert timelines and disagreement
Recent expert surveys put the median 50% probability for AGI sometime between roughly 2040 and 2061, though a vocal minority predicts much earlier dates.forbes+1
Some commentators then assume a relatively fast transition from AGI to ASI, with speculative ranges from a few years to several decades; one analysis frames a “useful estimate” of about 10 years from AGI to ASI.theaireport+1
At the same time, many experts (around three‑quarters in one survey) think simply scaling today’s techniques is not enough for AGI, let alone ASI.theaireport
Indicators of movement toward ASI
Rapid capability scaling: Benchmarks show steep year‑on‑year jumps in areas like multimodal understanding and software engineering, plus large drops in compute cost for a given capability level.hai.stanford+1
Early self‑improvement: Leading models can already optimize their own code or assist in model design, raising the question of whether this could ever “snowball” into open‑ended self‑improvement.scientificamerican+1
These trends are why some researchers argue we might be seeing the first steps toward systems that could one day underpin superintelligence, even if that point is still far away.scientificamerican
Cautious views and roadmaps
Researchers like Yann LeCun emphasize that even ambitious roadmaps aiming at “advanced machine intelligence” still expect only animal‑level world understanding (e.g., “cat or rat” level) prototypes within a few years, not human‑ or super‑human minds.eetimes
Groups branding themselves around “ASI” publish roadmaps that explicitly admit human‑level AGI has not yet been reached and present ASI as a longer‑term goal after major research advances.superintelligence
These more conservative views highlight that achieving robust world models, reasoning, and planning is still an unsolved problem.
How near are we, realistically?
No ASI today: There are no systems that fit the common definition of intelligence vastly beyond the best human experts across all domains.theaireport+1
AGI first, ASI later (if at all): Most structured analyses treat ASI as contingent on first achieving AGI, with a further uncertain period—possibly years to decades—before any superintelligent phase.forbes+1
Taken together, a reasonable reading of the evidence is: ASI is not imminent, serious people disagree on whether it is this‑century or ever, and the main near‑term focus is on managing rapidly strengthening but still fallible AI systems rather than on a concrete ASI arrival date.hai.stanford+2
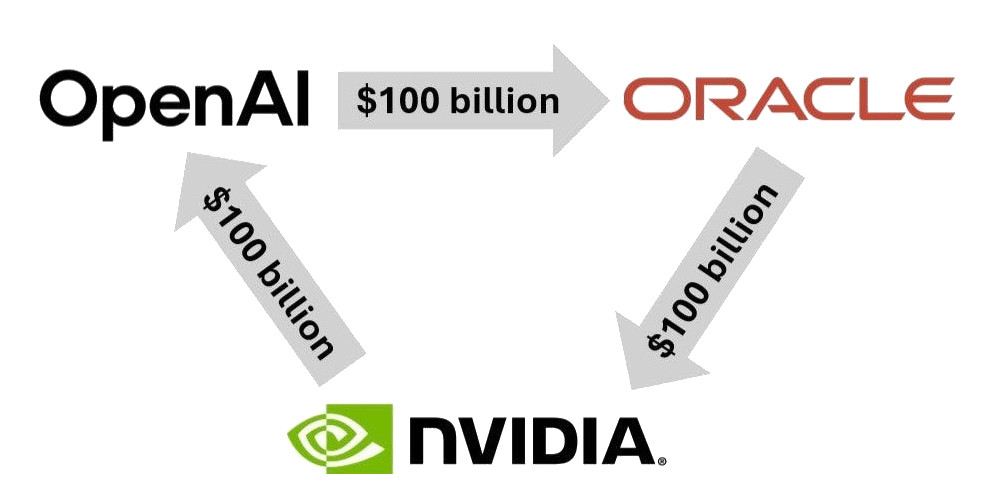
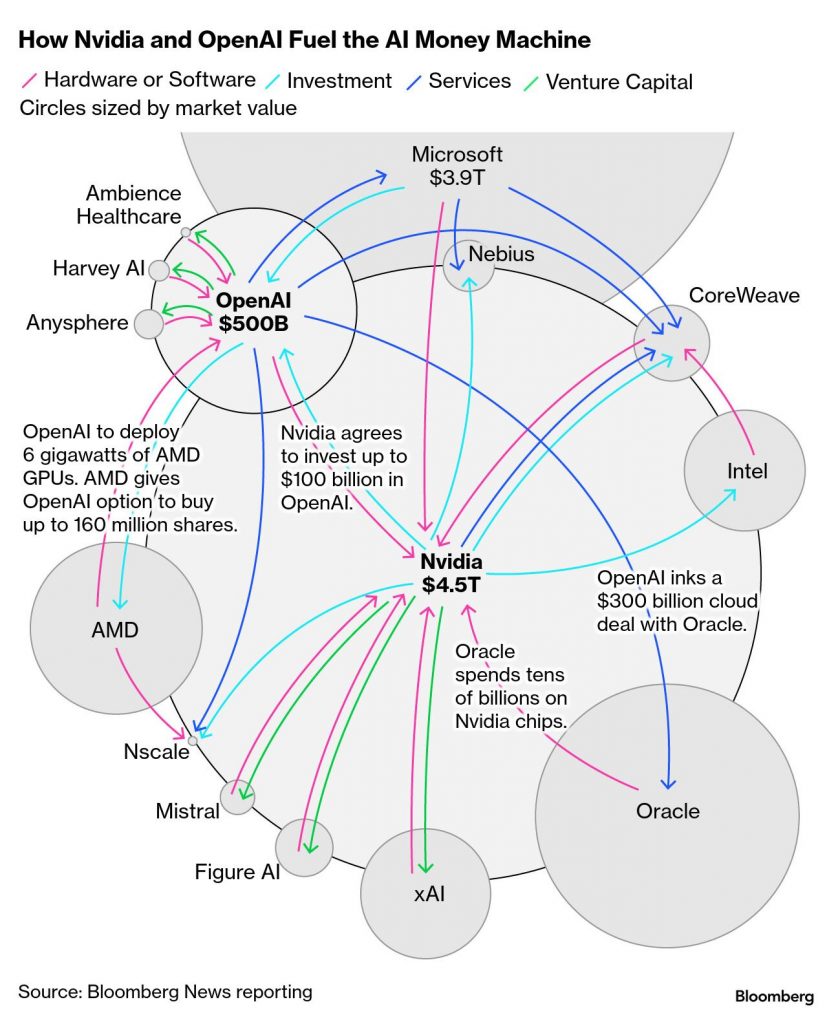
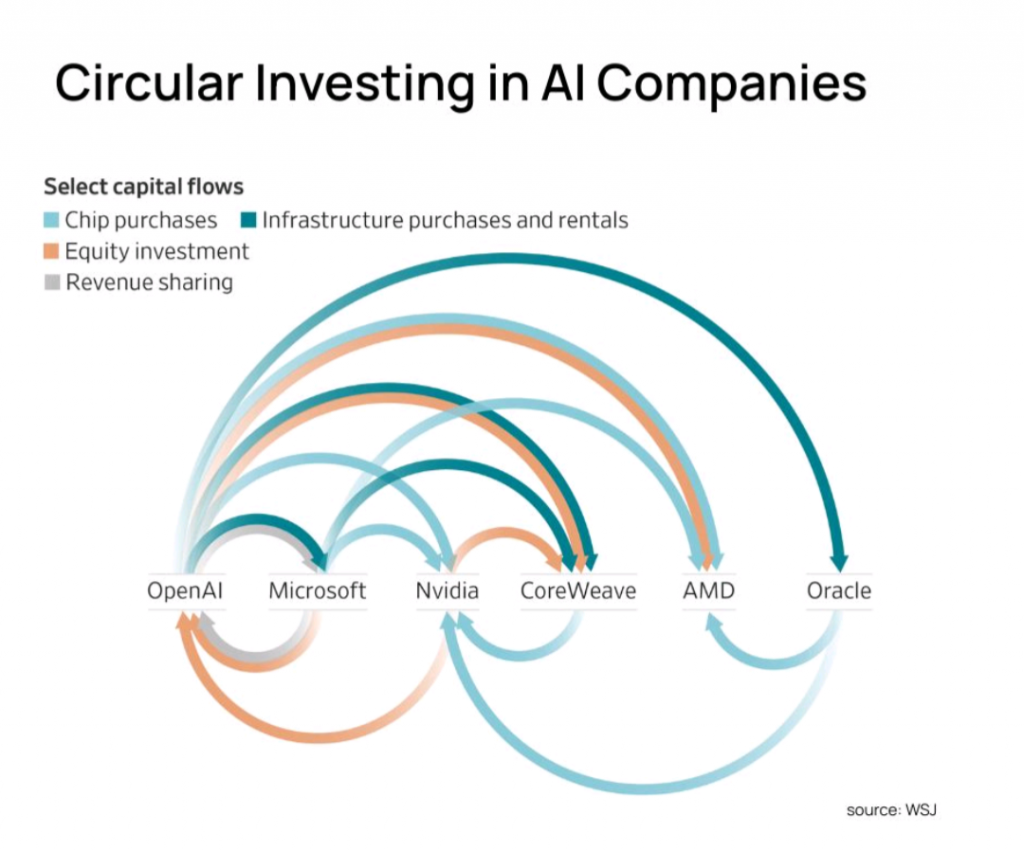
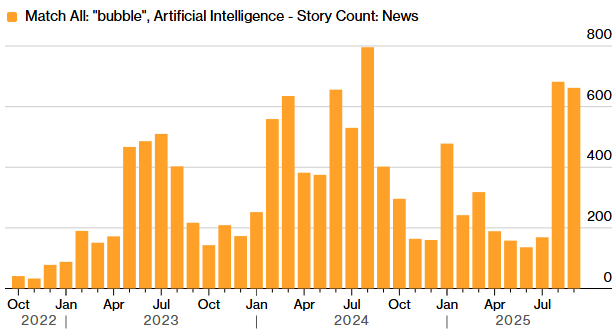
We’ve all seen the above image when Oracle started making waves about their AI contract to provide OpenAI compute power at their Abilene DC with tonnes of NVIDIA GPUs – well there’s now news about circular financing fraud involving the big AI players…
We look at what this article is saying and assess whether a postive circular financing fraud case will be the pin that bursts the AI bubble: https://substack.com/home/post/p-179453867
The article describes how advanced trading algorithms and machine intelligence detected an unprecedented $610 billion circular financing fraud involving major AI industry players, including Nvidia, Microsoft, OpenAI, Oracle, and xAI. This scheme involved companies repeatedly recycling the same money through chip purchases, cloud credits, and investments, allowing them to recognize fictitious revenue and inflate financial numbers without actual cash being exchanged.binance+3
What Happened
On November 20, 2025, AI-driven trading systems analyzed Nvidia’s earnings and discovered massive inconsistencies: billions in accounts receivable remained unpaid, and customers were taking longer to pay, resulting in aging bills and swelling inventories. The investigation revealed funds circulated between firms—such as Nvidia investing in xAI, which would use pushed loans to buy Nvidia chips, while Microsoft and Oracle funneled cloud credits through OpenAI—getting booked as revenue at multiple companies, but with no real payment behind the transactions.instagram+2
Impact on Financial Markets
Once the fraud was flagged, Nvidia’s stock, which had surged by $130 billion after earnings, quickly crashed as algorithms triggered selloffs faster than human analysts could respond. Bitcoin, used by many AI startups as loan collateral, also plunged as market confidence evaporated, with experts predicting further Bitcoin sell-offs as defaults increase.stockmarketanalysis04.substack+2
Industry Reactions and Fallout
Executives—including those from Airbnb and OpenAI—acknowledged the reliance on artificial “vibe revenue,” admitting the industry’s expected future profits were vastly overstated, and many projects would never deliver the anticipated returns. Famous investors quickly exited positions, and credit agencies are expected to downgrade the sector as payment cycles lengthen and the circular financing unwinds.news.futunn+2
Warnings and Criticism
Analysis of the reports cautioned that while some claims align with public financial data, other details appear speculative or exaggerated, casting doubt on the scale and specifics of the fraud presented in the article. However, the exposure of circular accounting practices has sparked renewed scrutiny of AI industry finances and the systemic risks they pose to both tech and broader financial markets.x+1
What would be the market implications if the fraud is confirmed?
If the $610 billion AI industry fraud is confirmed, the market implications would likely be severe and multifaceted:
Stock prices of the companies involved would likely experience sharp declines, similar to historic fraud cases where stock prices dropped significantly upon fraud discovery and investigation announcements. For example, firms have seen cumulative abnormal returns fall by 29% at fraud discovery and further 8% after regulatory investigation announcements, particularly when fraud involves revenue recognition or asset overstatement.nacva+1
Investor trust across the AI and related tech sectors would erode drastically, causing not only plummeting stock demand for the implicated companies but also collateral damage to wider market confidence. This loss of trust can depress sales, revenue, and overall financial performance beyond the direct fraud perpetrators.financemagnates
Increased regulatory scrutiny and enforcement actions would follow, including potential SEC investigations, fines, and legal consequences for perpetrators, shaking market stability and inviting tighter oversight on AI industry financial reporting.fraud+1
The revelation of such a large-scale circular financing scheme would raise concerns over information opacity and systemic risks in the AI sector and adjacent markets. This could raise the risk of future stock price crashes and long-term market volatility due to shaken investor confidence and greater caution toward AI-related investments.sciencedirect
Credit downgrades and withdrawal of investment capital across affected companies and startups would likely accelerate, hampering innovation financing and causing a sector-wide funding crunch.binance
Together, these effects imply a potential market shock comparable to major corporate fraud scandals, with profound short-to-medium term disruptions in AI industry valuations and investor behavior, and increased regulatory and due diligence focus on AI sector financial transparency.nacva+2
Which peer firms and sectors would face contagion risk?
If the $610 billion AI industry fraud is confirmed, the peer firms and sectors facing contagion risk would include:
Other major AI and technology firms interconnected via investments, chip sales, and cloud services, such as Microsoft, Oracle, OpenAI, and Nvidia’s competitors. Because the fraud involved circular financing among these players, their financial health and market valuations would be at risk of contagion through direct exposures and reputational damage.
The broader technology sector, including semiconductor manufacturers, cloud infrastructure providers, and AI startups, which depend heavily on investment flows and customer confidence linked to the implicated firms. Funding shortages and tighter credit conditions would ripple across these linked companies.
Financial institutions such as banks, investment funds, hedge funds, and insurers holding equity, debt, or derivatives tied to AI and tech firms. Market shocks from the fraud revelation could trigger liquidity strains, asset fire sales, and valuation drops across these financial intermediaries.
Sectors with strong dependence on AI-driven growth or technology investments, including software service companies, cloud computing, and innovative tech hardware industries, which would face heightened volatility and funding risks from cascading investor withdrawals.
In summary, the contagion risk would span a network of interlinked AI/tech firms, their financial backers (banks, funds, insurers), and adjacent sectors relying on AI-driven growth and innovation capital. These risks would be amplified by dense financial linkages, cross-holdings, and overlapping investor exposure, potentially escalating systemic risks and market instability across these interwoven sectors.ecb.europa+2
How likely is this a fraud?
The likelihood of this $610 billion AI industry fraud being real appears mixed, with some evidence supporting concerns but also significant skepticism about the full scale and details.
Support for fraud possibility: Automated algorithms detected unusual circular financing flows and discrepancies in accounts receivable, payments, and inventory levels among key players like Nvidia, OpenAI, Microsoft, and Oracle. Executives and industry insiders have acknowledged artificial revenue recognition practices, “vibe revenue,” and unsustainable burn rates, fueling suspicions of inflated financial reporting and reliance on self-referential capital cycling.reddit+2
Skepticism: Several data points in the original fraud claim articles do not fully align with official financial statements or audited reports. For example, some growth rates and cash conversion claims appear unverified or exaggerated, and robust revenue projections remain in place for major firms like Nvidia. Critiques suggest parts of the narrative may be speculative or amplified to support short-selling or competitive narratives.news.futunn+1
Market actions such as large insider sales, stock volatility, and algorithmic trading responses reflect real concerns but do not alone prove deliberate fraud.
Overall, while there is credible reason for regulatory scrutiny and investor caution, it is not yet conclusively proven that a $610 billion-scale fraud has occurred as portrayed. Financial markets and regulators will need to conduct thorough audits and investigations to confirm or refute the full extent of circular financing and unverifiable revenues in the AI sector.reddit+1
What additional evidence would confirm or refute the fraud claim?
To confirm or refute the $610 billion AI industry fraud claim, the following additional evidence would be critical:
Detailed audit reports and forensic accounting analyses that reveal whether reported revenues and assets align with actual cash flows, eliminating circular financing and fictitious transactions. Clear documentation of payment trails and verification of accounts receivable would be vital.
Access to internal communications, contracts, emails, and loan agreements showing intent, knowledge, or concealment of fraudulent practices among the companies involved. These would demonstrate deliberate misrepresentation rather than innocent errors.
Independent verification of inventories, customer payments, and cloud credit usage that purport to back financial figures, to detect any discrepancies or inflated valuations.
Testimonies or whistleblower accounts from insiders who can provide direct evidence of deception, revenue manipulation, or artificially inflated accounts.
Examination of algorithmic data and trading patterns that initially flagged the fraud, corroborated by hard financial evidence to remove speculation.
Legal scrutiny and regulatory investigations with power to compel document production and testimony, leading to formal findings of fraud based on a balance of probabilities.
These types of evidence collectively would build a persuasive case by proving the key elements of fraud: false statements of fact, knowledge of falsity, intent to deceive, reliance on the falsehood by others, and resulting financial damage.lincolnandrowe+3
Due to the big players involved, how like is this to be recognised as fraud?
Given the involvement of major public companies such as Nvidia, Microsoft, Oracle, and OpenAI, it is relatively less likely that the alleged $610 billion circular financing scheme would go unrecognized or uninvestigated by regulators, auditors, and independent analysts. These firms operate under strict financial reporting standards, are subject to continuous market scrutiny, and have audits performed by reputable firms. Nvidia, for example, is audited by PwC and rated highly by credit agencies, and recently reported strong revenue guidance despite allegations.news.futunn+1
However, the complexity and scale of circular financing and vendor financing deals—spread across multiple firms and private entities like OpenAI—and the extraordinary sums involved create challenges in transparency. Given the high stakes, any material misstatements or abuses would likely draw regulatory attention from bodies like the SEC, and investigations would follow, as evidenced by past fraud cases in tech and finance.peterwildeford.substack
Market reactions such as rapid stock sell-offs, insider selling, and investor withdrawals suggest heightened suspicion and the potential for increased scrutiny. But actual recognition of fraud depends on whether clear evidence emerges proving intent and knowing misrepresentation, beyond complex but possibly legitimate financial engineering.substack+1
Therefore, while these large players’ reputations, audit requirements, and regulator oversight make outright fraud recognition more probable than in less regulated sectors, proving the full scope involves thorough forensic audits and investigations. The high-profile nature ensures any verified fraud will be highly publicized and swiftly acted upon.tomtunguz+3
The public seems to be able to see this circular financing already, but there has been no obvious denies or evidence until now?
The public’s ability to observe the circular financing is likely due to the following:
Many of the so-called circular financing deals in AI are part of legitimate strategic partnerships, vendor financing, and ecosystem-building efforts. Companies like Nvidia, OpenAI, Microsoft, AMD, Broadcom, and others are deeply intertwined financially and operationally, investing heavily in each other through chip sales, equity stakes, and cloud infrastructure deals. This creates a “circular economy” that keeps capital flowing within a compact network, which is visible in market disclosures and company announcements but can appear as circular funding to outside observers.forbes+2
These circular arrangements often reflect business models designed to ensure long-term demand for AI hardware and cloud services while fostering innovation through close alliances. While they may inflate revenue temporarily on paper by recognizing sales within the network, such practices are also common vendor financing strategies used in many industries historically and are not necessarily fraudulent if transparently disclosed and compliant with accounting standards.reddit+1
Until now, there has been no obvious denial or strong rebuttal partly because companies benefit from these arrangements to drive AI ecosystem growth and financial performance, and the accounting treatments remain within legal frameworks. The lack of clear external evidence against them also means regulators and auditors have not formally challenged these practices as fraudulent yet, despite increasing scrutiny and skepticism among investors and algorithms detecting anomalies.bbc+1
The recent algorithmic detection of potential fraud has heightened attention and raised the stakes for transparency, but distinguishing aggressive vendor financing from deliberate fraud requires detailed forensic audit evidence and regulatory investigation.
Thus, the public is seeing signals of circular financing because it is foundational to how AI ecosystem finance currently operates, but formal fraud recognition demands deeper proof beyond visible financial flows circulating within interconnected big players.ubs+3
There isn’t going to be a single answer to why we are experiencing major global internet outages of late. There will be a number of reasons that are all coinciding to produce these recent occurrences.
Recognising these reasons will allow us to predict who is next after AWS, Azure and Cloudflare…
Why is today’s internet so fragile?
Recent outages at AWS, Azure, and Cloudflare have starkly exposed just how fragile today’s internet is, largely due to concentrated infrastructure, dependency on a handful of providers, and architectural choices that allow minor failures to trigger global disruptions.gulfnews+2
Extreme Centralization
The internet now relies heavily on a few “invisible” giants: AWS, Azure, Google Cloud, and Cloudflare together account for most global web traffic, hosting, routing, and security.techwireasia+1
Cloudflare alone accelerates and protects an estimated 20% of all internet traffic. When any of these services experience issues, disruption ripples across thousands of companies and billions of users, as seen in recent events.computing+1
Cascading Failures
Outages often start with technical errors such as DNS failures, network misconfigurations, or buggy software updates. Because so many services are built on top of these platforms, a seemingly small incident can snowball rapidly into crippling downtime across the world.modern-networks+1
For example, a DNS outage at AWS led to millions of user lockouts and stalled applications globally, while Cloudflare’s recent bug knocked out platforms like ChatGPT, X (Twitter), Spotify, and many SaaS tools all at once.deployflow+2
Lack of True Redundancy
While cloud vendors offer robustness at the hardware and software level, many applications and businesses still depend on single providers or even single cloud regions, lacking the architectural redundancy needed for true resilience.cnn+1
Multi-cloud designs are promoted as a solution, but adoption remains slow due to complexity and cost.economictimes+1
Legacy Internet Foundations
Critical protocols like DNS, which translate website names to machine addresses, are based on decades-old designs. If DNS fails at a major provider, or a bad configuration is cached globally, the effects can take hours or even days to fully resolve.techwireasia+1
Economic and Societal Risk
Because core digital payments, communications, and business tools are now web-based, cloud outages don’t just inconvenience consumers—they can disrupt financial markets, logistics, healthcare, and government.itbrief+1
Governments are beginning to treat cloud and network resilience as matters of national security, pushing for failover planning and measures against systemic risk.gulfnews+1
Driving the Future
These outages are accelerating moves to adopt decentralized architectures (Web3), distributed CDNs, and alternatives to centralized cloud platforms.gulfnews
Still, until broad and real decentralization is achieved, today’s internet remains vulnerable to concentrated points of failure—making global web fragility an ongoing and deeply technical challenge.cnn+1
Is the complexity of modern software, apps and services that make the internet brittle?
There is strong, concrete evidence that the rising complexity of software, applications, and IT services is directly making the internet more brittle and increasingly prone to outages.uptimeinstitute+2
How Complexity Drives Fragility
Modern applications are built on tightly interdependent components, microservices, APIs, and SaaS layers. Even minor changes—like a configuration tweak or a faulty software update—can cascade through interconnected systems, causing large-scale outages.ashrafmageed+1
Real-world outages, such as the infamous Facebook, AWS, and Azure disruptions, have repeatedly been traced back to software bugs, unexpected side effects between services, or misconfigurations in complex control planes.thousandeyes+1
Concrete Examples
The October 2021 Facebook outage resulted from a misconfiguration update that propagated through its global BGP (Border Gateway Protocol) infrastructure, causing a full disconnection from the internet—demonstrating how internal software complexity can have massive external effects.theintelligraph
The 2020 Azure and recent AWS outages were triggered by subtle software bugs or missteps in automated update pipelines. What began as isolated technical errors quickly led to global knock-on effects due to hidden dependencies and insufficient isolation between services.thousandeyes+1
The CrowdStrike security software update in 2024 caused mass Windows system crashes and “bootloops,” showing how a flaw in widely deployed software had a systemic effect far beyond one organization.news.exeter
Industry Data and Research
Reports from Uptime Institute and industry observers state that software, network, and configuration issues—many stemming from growing complexity—are the fastest-growing sources of critical IT outages. As architectures shift to the cloud, hybrid or multi-cloud forms, and “infrastructure as code,” the number of places where failure can originate multiplies.securitybrief+1
Complexity makes it harder for engineers to fully understand the system, increasing cognitive load. Documentation may lag, tests are often brittle, and adding new features or changing existing code can unintentionally break other parts of the stack, amplifying the risk of downtime.codurance+1
In Summary
Concrete evidence from industry reports, postmortems, and technical analyses shows that software and architectural complexity is now a leading cause of major outages across the internet and digital services.uptimeinstitute+2
As IT services and software systems become ever more entangled, even small mistakes or bugs can propagate, causing widespread disruption and emphasizing the need for simplicity, redundancy, and rigorous testing in critical systems.theintelligraph+1
The third reason for internet outages being more common and prevalent in the modern age
A third major reason internet outages are more common in the modern age is the increased frequency and sophistication of cyberattacks, including ransomware and targeted digital assaults on critical infrastructure.datacenter.uptimeinstitute+2
Cybersecurity Threats and Ransomware
Recent years have seen a rapid rise in outages caused by cyberattacks, especially ransomware campaigns and distributed denial-of-service (DDoS) attacks targeting cloud providers, SaaS platforms, and essential network infrastructure.telconews+1
These attacks can disable services, corrupt data, and sometimes require shutting down affected systems entirely for forensic investigation and restoration.datacenter.uptimeinstitute
As much as the physical and software layers have become more complex, new vulnerabilities are constantly emerging, and attackers exploit these with increasing speed and precision, making outages both more frequent and severe.teridion+1
Why This Is Rising
Greater digital transformation and cloud adoption have made critical services attractive and lucrative targets for cybercriminals.telconews+1
Even well-secured organizations are vulnerable to supply-chain attacks—where the compromise of a key vendor or upstream software provider can cascade globally and impact hundreds or thousands of customers at once.datacenter.uptimeinstitute
Research and industry analyses show that successful large-scale ransomware and cyber incidents are now among the leading triggers of major public outages, alongside centralization and complexity.telconews+1
In summary, cyberattacks—especially ransomware—represent a third key factor making internet outages more prevalent and impactful in the modern era, adding to the fragility created by centralization and increasing system complexity.teridion+2
Who will have the next outage that will affect the global internet?
Based on current evidence and industry analysis, the next global internet outage is most likely to be triggered by one of two sources: either a failure at a major cloud or infrastructure provider due to software or configuration errors, or a cyberattack targeting critical cloud services or undersea cables. However, there is also significant expert concern that a severe solar storm during the predicted Solar Maximum in 2025 could cause even wider disruption by damaging undersea cables and global communication infrastructure.financialexpress+2
Most Direct Triggers
Cloud Provider Error: Given recent patterns, a chain reaction sparked by a misconfiguration, flawed software update, or unexpected cascade within AWS, Azure, Google Cloud, or Cloudflare remains the most likely culprit for another major outage. The interconnected nature of cloud services means a localized issue can propagate system-wide in minutes.thousandeyes+1
Cyberattack: Large-scale, coordinated ransomware or DDoS campaigns are rising and present a considerable threat. Critical SaaS, CDN, and DNS infrastructure are prime targets. A breach in a major provider or a critical software library could affect thousands of businesses globally at once.reports.weforum+1
Solar Storm Risk
Solar Maximum 2025: Some experts now warn that natural events—specifically powerful solar storms—could damage undersea fiber links and data centers, causing internet outages far more widespread and unpredictable than anything to date. While rare, the impact could last for days or even months, with recovery depending on the ability to repair undersea infrastructure and restore communications.cnbctv18+1
Unpredictable Factors
It’s increasingly difficult to forecast who or what will cause the next global outage because architectures are more complex, attack surfaces are broader, and even well-intentioned updates or external environmental events can have devastating consequences.financialexpress+1
In summary, the next global internet outage is most likely to be created by a technical failure or attack affecting critical infrastructure (cloud, DNS, CDN), but severe space weather disruptions are also being seriously considered by experts for 2025.cloudflare+2
Among GCP (Google Cloud Platform), Broadcom, Oracle, IBM, Meta, and Apple, GCP carries the highest risk of causing the next global internet outage. This is due to its position as a major cloud service provider, with deep integration into SaaS, enterprise infrastructure, APIs, and many consumer services. Outages from cloud providers frequently propagate to thousands of dependent services and users worldwide, amplifying systemic impacts.insuranceinsider
Why GCP Is Most Likely
Cloud providers pose systemic risk because centralized cloud infrastructure hosts, manages, and routes massive portions of the world’s internet traffic.cybcube+1
GCP, while smaller than AWS and Azure, still represents a major aggregation point: it powers business-critical workloads (banking, retail, logistics), hosts thousands of SaaS platforms, and provides back-end APIs for many mobile apps and connected devices.insuranceinsider
Recent cloud incidents (AWS, Azure, Cloudflare) have proven how failures in authentication, DNS, or network configuration can quickly cascade to global impact, and GCP’s technical complexity and interconnections make it vulnerable to similar risks.piranirisk+1
Risk Assessment of Others
Broadcom: While it designs key hardware and networking gear, it is less likely to directly trigger a software or routing-linked global outage at internet scale. Its risks are supply-chain and chip-related, not service aggregation.carnegieendowment
Oracle, IBM: Both power significant enterprise IT, but they are not primary cloud or content routing platforms for consumer web services. Oracle Cloud is growing but has not reached the single-point-of-failure scale of GCP or AWS.insuranceinsider
Meta, Apple: Outages from these can severely disrupt social media or device ecosystems, but they do not underlie the broad global infrastructure dependencies typical of a cloud provider failure.carnegieendowment
Industry Consensus
Reports and regulators consistently identify major cloud providers as critical “single points of failure.” When cloud aggregation, concentration, and technical complexity are considered, GCP ranks highest within your list for systemic outage risk.cybcube+1
In summary, GCP is the most likely among your choices to trigger the next global-scale outage, because cloud providers are at the heart of internet infrastructure and software dependencies today.cybcube+1
It is no secret that I am leaving Oracle to join Nscale at the end of this month. My main aim was to avoid the Oracle RIF/layoffs and while putting the worse case scenario in place, I managed to get a role at Nscale.
Both Oracle and Nscale are hedging their bets on AI and with the current worry that the AI bubble is going to burst, with the boss of Google saying: ‘no company is going to be immune’ [BBC], I asked AI these questions…
How Oracle would suffer in an AI crash?
Oracle would experience significant financial and operational setbacks if an AI crash occurs, mainly because its recent strategy has focused heavily on AI cloud infrastructure and hyperscaler partnerships. Here’s how Oracle and Oracle Cloud Infrastructure (OCI) would suffer:
Revenue Slowdown and Underutilized Data Centers
Oracle expects that AI-driven cloud infrastructure could make up the majority of its revenue by 2030, with multi-billion dollar GPU investments and flagship deals supporting OpenAI, Meta, and other hyperscale model trainers.webpronews+1
In an AI crash, client demand for large-scale training and inference workloads would sharply decline. That means Oracle’s new data centers and GPU fleets (including hundreds of thousands of Nvidia GPUs) could become underutilized, forcing write-downs and lowering ROI.fortune
Margin Compression and Volatility
Oracle’s current margins on AI cloud offerings are modest (around 14% in recent quarters), and plans for improvement depend on scale and full utilization of infrastructure.bloomberg+1
Reduced client activity would keep margins low or negative, intensifying investor scrutiny and driving downward pressure on stock price—recent volatility already shows concern over fulfilling ambitious AI cloud predictions.cnbc+1
Oracle would also struggle to justify continued massive investments to shareholders if growth fails to materialize.
Exposure to Contract and Customer Risk
Oracle is especially exposed to a few large anchor clients (e.g. OpenAI, Microsoft), who may defer or downsize contracts if the economics of large-model training weaken.webpronews+1
Cancellations or renegotiations on these hyperscale deals would lead to revenue instability and possible reputational harm in the cloud sector.
Delayed Application Growth and Broader Impact
While Oracle’s core application business (ERP, NetSuite, traditional cloud services) offers some revenue buffer, these divisions would also be affected by a broader tech and enterprise spending slowdown typical in an AI-induced market downturn.constellationr+1
Expansion plans and R&D investment would likely be scaled back, slowing Oracle’s ability to compete with more insulated rivals.
Summary Table: Oracle’s Pain Points in an AI Crash
Effect Area
Oracle Cloud & Business Impact
Infrastructure ROI
Underutilized data centers, GPU fleets
Margins & Profit
Margin compression, stock volatility
Contract Risk
Deferred/canceled hyperscale projects
App/Enterprise Spend
Revenue dampening, slower growth
In summary, Oracle would suffer via underperforming cloud assets, margin pressure, dependency on a handful of high-risk AI clients, and contraction of enterprise demand. While traditional non-AI applications offer some shelter, the scale of Oracle’s recent AI cloud bets makes it highly exposed to a major market correction.reuters+6
How Nscale would be affected by an AI crash?
Nscale would be severely affected by an AI crash due to its intense reliance on hyperscaler contracts, rapid capital deployment, and debt-financed AI infrastructure builds. Its business model is specifically geared toward serving large-scale AI model training and compute workloads, making it one of the highest-risk startups in a downturn scenario.
Revenue Freeze and Stranded AI Data Centers
If AI demand collapses, hyperscalers like Microsoft and OpenAI—Nscale’s anchor clients—would scale back their contracts, delay GPU purchases, or walk away from expansion phases, freezing Nscale’s main cashflow pipeline.computing
Data centers built for intensive model training could be left mostly idle, forcing Nscale to absorb heavy operational losses while continuing to service debt and lease obligations.
Investor and Debt Pressure
Nscale’s recent $1.1 billion Series B and $433 million SAFE financing involve a mix of industrial and venture capital (Aker, Nvidia, Dell, Blue Owl), and depend on optimistic growth projections and future contract fulfillment.cnbc+3
In a crash, these investors would likely mark down their stakes significantly, making further fundraising difficult. If cash flow dries up, Nscale could face covenant breaches, mass layoffs, and possibly insolvency.
Asset Write-Downs and Market Value Declines
Large inventories of Nvidia GPUs and purpose-built data centers for AI workloads could lose much of their resale value if a flood of surplus infrastructure hits the market simultaneously.computing
Hardware and campuses not suited for general-purpose workloads would be especially vulnerable—mirroring the fate of unused “dark fiber” and crypto-mining assets after previous speculative bubbles burst.
Strategic Pivot and Survival Pathways
With deep exposure to hyperscaler deals, Nscale’s best shot at survival would be pivoting toward government-backed sovereign compute projects, or repositioning under-utilized capacity for scientific, academic, or inference-driven workloads.computing
However, the overall scale-back in AI investment would make even these pivots challenging and may require restructuring, asset sales, or merger activity.
Summary Table: Nscale’s Crash Exposure
Pain Point
Crash Impact
AI contract reliance
Revenue freeze, phased-out deals, layoffs
Infrastructure assets
Write-downs, idle data centers, GPU oversupply
Investor relations
Markdowns, covenant risk, fundraising difficulty
Pivot opportunities
Limited to sovereign or non-AI workloads
In summary, Nscale would be among the hardest-hit AI infrastructure startups during a crash, facing immediate cash flow problems, asset devaluation, and existential threats unless it rapidly adapts or receives protective strategic support.uktech+4
As an employee of Oracle or Nscale – who would be worst affected in an AI crash?
As an employee, Nscale staff would likely be much worse affected by an AI crash than Oracle employees. This is due to the relative scale, business diversity, and risk tolerance of the two companies:
Nscale Employees: High Risk
Startup Vulnerability: Nscale is a high-growth, venture-backed startup focused almost entirely on the AI cloud hyperscaler market. If an AI crash occurs, Nscale would face abrupt revenue freezes, contract withdrawals, and rapid asset devaluation, with far less financial cushion to weather losses than a large incumbent like Oracle.
Layoffs and Insolvency Risk: In a crash, Nscale may be forced to lay off a substantial portion of its workforce quickly, pause projects, or even enter administration if funding evaporates or debts cannot be serviced. Employees could face sudden job loss, delayed salaries, and loss of equity value, with fewer internal opportunities for reassignment.
Equity and Options: Most compensation upside for Nscale staff is likely tied to startup equity. A market correction would deeply devalue or wipe out employee options/shareholdings, and prospects for another lucrative exit (e.g., IPO or acquisition) would diminish drastically.
Oracle Employees: More Stability, Less Immediate Risk
Diversified Business: Oracle is a global enterprise with diversified revenue streams across cloud, applications, hardware, licensing, and services. Even with heavy AI investment, its overall risk is spread out, and core business lines would remain resilient.
Less Severe Layoffs: Large tech companies like Oracle do enact layoffs in downturns, but they tend to be more measured and spread across divisions. Employees have more options to transfer internally or leverage severance and career support programs.
Compensation Impact: Public company employees with RSUs or stock options would feel a drop in value, but these tend to recover after corrections, and overall job security remains higher due to Oracle’s operational scale and financial reserves.
Summary Table
Factor
Nscale Employee Impact
Oracle Employee Impact
Layoff risk
Extremely high, abrupt
Moderate, measured
Job security
Low
High
Equity/option value
Likely wiped out
Lower, but more resilient
Internal mobility
Minimal
Significant
Corporate backup/support
Minimal/none
Substantial
In summary: Nscale employees are far more exposed to job loss, equity wipeout, and uncertainty during an AI crash, while Oracle employees—even in affected AI-focused roles—would generally be shielded by the company’s size, global reach, and business diversity.
What is the benefits of joining Nscale for my career over staying at Oracle
Joining Nscale instead of staying at Oracle offers a profoundly different set of career benefits and risks. Your choice should be shaped by your appetite for growth, impact, compensation profile, and risk tolerance.
Career Acceleration and Impact
Rapid Responsibility & Visibility: At Nscale, a high-growth AI infrastructure startup, you’re likely to hold broader responsibilities, have a direct line to executives, and see tangible impact from your contributions—versus a more specialized, hierarchical environment at Oracle.linkedin+1
Cutting-Edge Technology Exposure: Nscale’s business is centered around the latest in AI hyperscale, GPU clusters, and sovereign compute, putting you at the heart of Europe’s most ambitious AI and cloud projects. This hands-on work accelerates technical learning and keeps you current with elite tooling.linkedin
Networking Opportunity: Being at a much talked-about scaleup, you’ll interact with top-tier industry partners (Microsoft, Nvidia, blue-chip VCs), as well as the fast-moving European AI ecosystem, which can boost professional reputation and future opportunities.cnbc+1
Compensation and Equity
Equity Upside: As with most startups, joining Nscale comes with employee equity—potentially life-changing financial upside if the company’s rapid growth leads to a successful IPO or acquisition. At Oracle, equity is usually granted as RSUs whose upside, while substantial, is tied to a mature company’s slower growth trajectory.
Compensation Mix Changes: Startup salary may be lower or matched to Oracle’s, but total comp potential is usually tied more to company performance and exit events.
Innovation, Learning and Influence
Innovation Environment: Nscale’s pace and hunger for innovation generally surpass what’s possible at a large, diversified incumbent like Oracle. Progression can be much faster for high performers at a startup, and you have more say in technical and strategic direction.
Learning Curve: The breadth of challenges—from scaling infra to winning deals and iterating products for hyperscaler clients—means you’ll develop skills quickly that are valuable for future founding roles, CTO posts, or senior technical leadership.
Risks, Trade-Offs and Stability
Job and Financial Risk: As shown in your AI crash scenario queries, Nscale is exposed to sector volatility. Layoff, equity wipeout, or strategic pivots are real risks in a downturn, while Oracle offers much greater job security and stable, long-term career pathways.
Work-Life Balance: Startups typically expect longer hours and intense focus, often trading stability for the chance at rapid advancement and financial gain.
Summary Table: Nscale vs Oracle Career Benefits
Career Factor
Nscale (Startup)
Oracle (Enterprise)
Career acceleration
Very high—fast progression, impact
Slower, more structured
Tech exposure
Latest/bleeding-edge AI/GPU work
Solid, broad enterprise stack
Compensation upside
High equity, risky
Stable salary, predictable RSUs
Job security
Low—volatile, high layoff risk
High, robust to market downturns
Influence
Large, direct access to leadership
Smaller, part of larger organization
Work-life balance
Often demanding
Generally more moderate
Networking
Top-tier VCs, hyperscalers, founders
Global enterprise contacts
In summary: Nscale offers a “rocket ship” growth and learning environment for someone hungry for ownership, innovation, and possible equity windfall—but this comes with higher risk and volatility. Oracle provides greater long-term job security, measured career progression, and reliable compensation, but less potential upside and less direct influence. The right choice depends on your risk appetite, ambition, and career goals.uktech+2
An AI crash would resemble a hybrid of the 1990s dot-com bust and the 2008 financial crisis—but centered around artificial intelligence infrastructure, data centers, and corporate overinvestment. It would likely begin as a sudden market correction in overvalued AI firms and GPU suppliers, then spread through the financial system and tech economy as debt and demand collapse.
Market and Investment Collapse
In early stages, overleveraged companies like OpenAI, Anthropic, or firms heavily reliant on GPU compute (e.g., Nvidia, Oracle, Microsoft) would face sharp valuation drops as AI-generated revenues fail to justify trillion-dollar capital expenditures. Investor panic could trigger a chain reaction, collapsing the leveraged network of data‑center finance. Bloomberg and the Bank of England have both warned of a “sudden correction” and circular investing between chip firms and hyperscalers that artificially props up earnings.transformernews+1
The Data Center Bust
According to historian Margaret O’Mara and business analyst Shane Greenstein, AI data centers—many purpose‑built for model training using GPUs—are highly specialized and often remote from urban demand. These centers might last only 3–5 years and have little reuse value outside AI or crypto mining. If capital inflows freeze, thousands of megawatts of compute could become stranded assets, comparable to the empty fiber networks after the dot‑com collapse.transformernews
Economic Impact
The International Monetary Fund estimates roughly a third of current US GDP growth depends on AI-related investment. If the bubble bursts, consumption could fall from loss of “AI wealth effects,” dragging global markets into recession. Analysts at Transformer News liken it to Britain’s 1840s railway mania: vast sums invested in technology that ultimately enriched the future economy—at the cost of investors’ ruin.globalcapital+2
Consequences for Jobs and Technology
For the workforce, the crash would begin with mass layoffs across the tech sector and data‑center construction, followed by second‑order layoffs in software, marketing, and education technology. However, as with the post‑dot‑com era, redundant talent and abandoned infrastructure could later fuel a new, leaner AI industry based on sustainable business models.reddit+2
Systemic and Political Risks
While the contagion risk is smaller than subprime mortgages in 2008, debt-financed AI expansion—Oracle’s $100 billion borrowing plan with OpenAI being one example—creates vulnerability for lenders and investors. Should a major firm default, cascading insolvencies could ripple through the supply chain, forcing governments to intervene. Some analysts expect this crash would prompt stricter AI regulation and financing guardrails reminiscent of those enacted after the Great Depression.transformernews
Long-Term View
If artificial general intelligence (AGI) does eventually deliver major productivity gains, early investments may appear prescient. But if not, a 2020s AI crash would leave disused GPU campuses and massive debt—an exuberant experiment that accelerated technological progress at ruinous human cost.unherd+2
Which industries would collapse first in an AI crash
In the event of an AI crash, several sectors would be hit first and hardest — especially those that have overexpanded based on speculative expectations of AI-driven profits or infrastructure demand. The collapse would cascade through high-capex industries, ripple across financial services, and disrupt employment-dependent consumer sectors.
Semiconductor and GPU Manufacturing
The semiconductor industry would be the first to collapse due to its heavy dependence on AI demand. Data center GPUs currently drive over 90% of Nvidia’s server revenue, and the entire sector’s value nearly doubled between 2024 and 2025 based on AI compute growth forecasts. If hyperscaler demand dries up, the oversupply of GPUs, high-bandwidth memory (HBM), and AI ASICs could cause a price crash similar to the telecom equipment bust in 2002. Chip makers and startups like Groq, Cerebras, and Tenstorrent—heavily leveraged to AI workloads—would struggle to survive the sudden capital freeze.digitalisationworld
Cloud and Data Center Infrastructure
AI-heavy cloud providers such as Microsoft Azure, AWS, Google Cloud, and Oracle Cloud would see massive write-downs in data center assets. Overbuilt hyperscale and sovereign AI campuses could become stranded investments worth billions as training workloads decline and electricity costs remain high. This dynamic mirrors the way dark fiber networks from the 1990s dot-com era lay idle for years after overinvestment.digitalisationworld
Digital Advertising and Marketing
The advertising and media sector—already experiencing erosion due to AI‑generated content—would decline abruptly. Companies like WPP have already lost 50% of their stock value in 2025 due to automated ad-generation technologies cannibalizing human creative work. As AI content generation saturates the market, profit margins in marketing, online publishing, and synthetic media platforms like Shutterstock and Wix could collapse.ainvest
Financial and Staffing Services
Financial services and staffing firms are another early casualty. AI has already automated large portions of transaction processing, compliance, and manual recruitment. Firms such as ManpowerGroup and Robert Half have reportedly seen 30–50% market value declines due to these pressures. In an AI crash, their exposure to risk-laden corporate clients and shrinking demand for human labor matching would deepen losses, while regulators tighten AI governance in compliance-heavy finance.ainvest
Transportation and Logistics
The transportation and logistics sector, closely tied to AI investment through autonomous systems, faces structural weakness. Millions of driving and delivery jobs could disappear due to automation, but the firms funding autonomous fleets—such as Tesla Freight and Aurora Innovations—would hemorrhage cash if capital dries up before widespread profitability. AI‑powered routing and warehouse systems could be written down as expensive overcapacity.ainvest
Secondary Collapse: Retail and Customer Support
Finally, customer‑facing retail and support sectors would be heavily affected. With AI chatbots now handling about 80% of common queries, these labor markets are already contracting. A market shock would worsen layoffs while eroding spending power, compounding the downturn.ainvest
In short, the first phase of an AI crash would decimate GPU suppliers and infrastructure providers, followed by cascading losses in services and labor markets that relied on sustained AI adoption and speculative investor optimism.
The Hyperscalers who would be most affected in an AI crash
The hyperscalers most severely affected by an AI crash would be those that have sunk the largest capital into AI‑specific data center expansion without commensurate returns—primarily Microsoft, Amazon (AWS), Alphabet (Google Cloud), Meta, Oracle, and to a lesser extent GPU‑specialist partners like CoreWeave and Crusoe Energy Systems. These companies are deep in an investment cycle driven by trillion‑dollar valuations and multi‑gigawatt data center commitments, meaning a downturn would cripple balance sheets, strand assets, and force major write‑downs.
Microsoft
Microsoft is the hyperscaler most exposed to an AI collapse. It has committed $80 billion for fiscal 2025 to AI‑optimized data centers, largely to support OpenAI’s model training workloads on Azure. Over half this investment is in the U.S., focusing on high‑power, GPU‑dense facilities that may become stranded if demand for model training plunges. The company also co‑leads multi‑partner mega‑projects like Stargate, a $500 billion AI campus venture involving SoftBank and Oracle.ft+1
Amazon Web Services (AWS)
AWS is next in risk magnitude, with $86 billion in active AI infrastructure commitments spanning Indiana, Virginia, and Frankfurt. Many of its new campuses are dedicated to AI‑as‑a‑Service workloads and custom silicon (Trainium, Inferentia). If model‑training customers scale back, AWS faces overcapacity in power‑hungry clusters designed for sustained maximum utilization. Analysts warn that such facilities are difficult to repurpose for general cloud usage due to 10× higher rack power and cooling loads.thenetworkinstallers+1
Alphabet (Google Cloud)
Google’s parent company, Alphabet, has pledged around $75 billion in AI infrastructure spending in 2025 alone—heavily concentrated in server farms for Gemini model operations. The company’s shift to AI‑dense GPU clusters has already required ripping and rebuilding sites mid‑construction. In a crash, Alphabet’s reliance on advertising to subsidize capex would expose it to compounding financial stress.ft+1
Meta
Meta’s risk is driven by scale and ambition rather than cloud dependency. The company is investing $60–65 billion into a network of AI superclusters, including a 2 GW data center in Louisiana designed purely for model training. Mark Zuckerberg’s goal to reach “superintelligence” entails constant full‑load operation—meaning unused compute in a recession would yield enormous sunk‑cost losses.hanwhadatacenters+1
Oracle
Oracle, a late entrant to the hyperscaler race, ranks as the fourth largest hyperscaler and has become deeply tied to OpenAI’s infrastructure build. It is reportedly providing 400,000 Nvidia GPUs—worth about $40 billion—for OpenAI’s Texas and UAE campuses under the Stargate project. Oracle’s dependency on a few high‑risk customers makes it vulnerable to disproportionate collapse if those clients cut capital expenditures.ft
GPU Cloud Specialists (CoreWeave, Crusoe, Lambda)
Although smaller in scale, CoreWeave, Crusoe Energy Systems, and Lambda Labs face acute financial danger. Each is highly leveraged to GPU leasing economics that assume near‑continuous utilization. A pause in large‑model training would break their cash flow structure, causing defaults among the so‑called “neo‑cloud” providers.hanwhadatacenters
A sustained AI market collapse would first hit these hyperscalers through GPU underutilization, stranded data‑center capacity, and debt‑heavy infrastructure financing. Microsoft, Oracle, and Meta would face the most immediate write‑downs given their recent megaproject commitments. Amazon and Google, while financially stronger, would absorb heavy revenue compression. Specialized GPU‑cloud providers—CoreWeave, Crusoe, and Lambda—could fail outright due to funding constraints and dependence on short‑term AI demand surges.thenetworkinstallers+2
Hyperscalers are the giants of cloud computing — companies that design, build, and operate massive, global-scale data center infrastructures capable of scaling horizontally almost without limit. The term “hyperscale” refers to architectures that can efficiently handle extremely large and rapidly growing workloads, including AI training, inference, and data processing.
Examples:
Amazon Web Services (AWS)
Microsoft Azure
Google Cloud Platform (GCP)
Alibaba Cloud
Oracle Cloud Infrastructure (OCI) (smaller but sometimes included)
These companies have multi-billion-dollar capital expenditures (CAPEX) in data centers, networking, and custom hardware (e.g., AWS Inferentia, Google TPU, Azure Maia).
What Are Traditional AI Compute Cloud Providers?
These are smaller or more specialized providers that focus specifically on AI workloads—especially training and fine-tuning large models—often offering GPU or accelerator access, high-bandwidth networking, and lower latency setups.
Examples:
CoreWeave
Lambda Labs (Lambda Cloud)
Vast.ai
RunPod, Paperspace, FluidStack, etc.
They often use NVIDIA GPUs (H100, A100, RTX 4090, etc.) and emphasize cost-efficiency, flexibility, or performance for ML engineers and researchers.
Key Comparison: Hyperscalers vs. AI Compute Cloud Providers
Dimension
Hyperscalers
AI Compute Cloud Providers
Scale & Reach
Global, thousands of data centers; integrated with enterprise ecosystems
Simpler, often cheaper hourly or spot pricing; more transparent GPU pricing
Performance Focus
Balance of general-purpose and AI-specific workloads
Focused almost entirely on deep learning performance
Networking
Proprietary, very high bandwidth and reliability
Can vary; some are optimized for high interconnect (e.g., NVLink, InfiniBand)
Ecosystem & Integration
Tight integration with DevOps, databases, storage, analytics, security, identity
Lightweight—focused mainly on compute, with minimal frills
Flexibility
Broad platform: supports everything from web hosting to LLM training
Narrow focus: mainly training, inference, and fine-tuning workloads
Target Users
Large enterprises, governments, global-scale AI projects
Startups, researchers, model trainers, boutique AI labs
Innovation Cycle
Slower—must maintain enterprise stability
Faster—can pivot quickly to support new GPUs or AI frameworks
Example Use Case
Multi-cloud enterprise AI strategy integrating ERP + data lakes + model deployment
Cost-effective fine-tuning or inference serving for startups
How They’re Converging
There’s an emerging hybrid trend:
Hyperscalers are building specialized AI infrastructure (e.g., NVIDIA DGX Cloud partnerships, Microsoft–OpenAI collaboration, Google DeepMind integration).
Smaller AI compute providers are adding orchestration layers (e.g., API management, distributed training schedulers) to resemble mini hyperscalers.
Some mid-tier players like Oracle, IBM Cloud, and Tencent Cloud are positioning themselves between these two worlds — offering both enterprise reliability and AI specialization.
In Summary
Hyperscalers = scale, reliability, and enterprise integration; ideal for end-to-end AI systems.
AI Compute Clouds = agility, affordability, and specialization; ideal for developers or teams training and serving models directly.
Would you like me to include a comparison of cost-performance ratios for AI workloads (e.g., GPT model training on A100s vs TPUs vs custom silicon)? That can show where each platform has an advantage.
Some Emergent Hyperscalers
Nscale — a vertically-integrated AI data-centre / GPU cloud scale-play (rapidly expanding via large GPU supply deals and data-centre buildouts). nscale.com+1
CoreWeave — GPU-first cloud operator focused on ML/graphics workloads; positions itself as lower-cost, fast access to new NVIDIA hardware. CoreWeave
Lambda Labs (Lambda Cloud) — ML-first cloud and appliances for researchers and enterprises; early to H100/HGX and sells private clusters. lambda.ai
Vast.ai — a marketplace/aggregator that connects buyers to third-party GPU providers for low-cost, on-demand GPU rentals. Vast AI
RunPod — developer-friendly, pay-as-you-go GPU pods and serverless inference/fine-tuning; emphasizes per-second billing and broad GPU options. Runpod+1
Paperspace (Gradient / DigitalOcean partnership) — easy UX for ML workflows, managed notebook/cluster services; targets researchers and smaller teams. paperspace.com+1
FluidStack — builds and operates large GPU clusters / AI infrastructure for enterprises; touts low cost and large cluster deliveries (recent colocation/HPC deals). fluidstack.io+1
Nebius — full-stack AI cloud aiming at hyperscale enterprise contracts (recent large Microsoft capacity agreements and public listing activity). Nebius+1
Iris Energy (IREN) — originally a bitcoin miner now pivoting to GPU colocation / AI cloud (scaling GPU fleet and data-centre capacity). Data Center Dynamics+1
Comparison table
Provider
Business model
Typical hardware
Pricing model
Typical customers
Notable strength / recent news
Nscale
Build-own-operate AI data centres + sell GPU capacity
NVIDIA GB/B-class & other datacentre GPUs (mass GPU allocations)
Enterprise deals / reservations + cloud access
Large enterprises, cloud partners
Large GPU supply deals with Microsoft; fast expansion. nscale.com+1
Practical differences that matter when you pick one
Business model & reliability
Marketplace providers (Vast.ai) are great for cheap, experimental runs but carry variability in host reliability and support. Vast AI
Dedicated GPU clouds (CoreWeave, Lambda, FluidStack, Nebius, Nscale, Iris) provide more predictable SLAs and engineering support for production/federated training. nscale.com+4CoreWeave+4lambda.ai+4
Access to bleeding-edge hardware
Lambda and CoreWeave emphasize fast access to the newest NVIDIA stacks (H100, HGX/B200, etc.). Good if you need peak FLOPS. lambda.ai+1
Pricing predictability vs lowest cost
RunPod / Vast.ai / Paperspace often win on price for small / short jobs (per-second billing, spot marketplaces). For large, sustained runs, enterprise contracts with Nebius / Nscale / FluidStack or reserved capacity at Lambda/CoreWeave may be more cost-efficient. Runpod+2Vast AI+2
Scale & strategic partnerships
Nebius and Nscale are scaling via huge supply agreements and data-centre builds aimed at enterprise contracts (Microsoft news for both). That makes them candidates if you need tens of thousands of GPUs or long-term buying power. Reuters+1
Operational maturity & support
CoreWeave, Lambda, and Paperspace have mature dev experience / tooling and are used widely by ML teams. FluidStack and the miner pivots (Iris Energy) are moving fast into HPC/colocation and can offer very large capacity but may require more custom engagement. irisenergy.gcs-web.com+4CoreWeave+4lambda.ai+4
Experimentation / cheapest short runs: Vast.ai or RunPod. Vast AI+1
Research / fast access to newest GPUs: Lambda or CoreWeave. lambda.ai+1
Large-scale, enterprise training / long contracts: Nebius, Nscale, FluidStack, or Iris (colocation + committed capacity). Data Center Dynamics+3Reuters+3Reuters+3
Oracle Cloud Infrastructure (OCI) vs Nscale (as of October 19, 2025). I’ll cover: company profiles, business models, core products & hardware, scale & geography, networking/storage, pricing & commercial approach, enterprise features & ecosystem, strengths/weaknesses, risk factors, and recommended fit / use cases. I’ll call out the most important, source-backed facts inline so you can follow up.
OCI vs Nscale
OCI (Oracle Cloud Infrastructure) — Enterprise-grade public cloud from Oracle with a full-stack platform (150+ services), strong emphasis on bare-metal GPU instances, low-latency RDMA networking, and purpose-built AI infrastructure (OCI Supercluster) for very large-scale model training and enterprise workloads. Oracle+1
Nscale — A rapidly-scaling, GPU-focused AI infrastructure company and data-center operator (spinout from mining heritage) that is building hyperscale GPU campuses and selling large blocks of GPU capacity to hyperscalers and cloud partners — recently announced a major multi-year / multi-100k GPU deal with Microsoft and is positioning itself as an AI hyperscaler engine. Reuters+1
1) Business model & target customers
OCI: Full public cloud operator (IaaS + PaaS + SaaS) selling compute, storage, networking, database, AI services, and enterprise apps to enterprises, large ISVs, governments, and cloud-native teams. OCI competes with AWS/Azure/GCP on breadth and with a particular push on enterprise and large AI workloads. Oracle+1
Nscale: Data-centre owner / AI infrastructure supplier that builds, owns, and operates GPU campuses and sells/leases capacity (colocation, wholesale blocks, and managed deployments) to hyperscalers and strategic partners (e.g., Microsoft). Nscale’s customers are large cloud/hyperscale buyers and enterprises needing multi-thousand-GPU scale. Reuters+1
Takeaway: OCI is a full cloud platform for a wide range of workloads; Nscale is focused on delivering raw GPU capacity and hyperscale AI facilities to large customers and cloud partners.
2) Scale, footprint & recent milestones
OCI: Global cloud regions and an enterprise-grade service footprint; OCI advertises support for Supercluster-scale deployments (hundreds of thousands of accelerators per cluster in design) and already offers H100/L40S/A100/AMD MI300X instance families. OCI emphasizes multi-region enterprise availability and managed services. Oracle+1
Nscale: Growing extremely fast — public reports (October 2025) show Nscale signing an expanded agreement to supply roughly ~200,000 NVIDIA GB300 GPUs to Microsoft across data centers in Europe and the U.S., plus earlier multi-year deals and very large funding rounds to build GW-scale campuses. This positions Nscale as a major new source of hyperscale GPU capacity. (news: Oct 15–17, 2025). Reuters+1
Takeaway: OCI provides a mature, globally distributed cloud platform; Nscale is an emergent, fast-growing specialist whose business is specifically bulking up GPU supply and datacenter capacity for hyperscalers.
3) Hardware & AI infrastructure
OCI: Provides bare-metal GPU instances (claimed as unique among majors), broad GPU families (NVIDIA H100, A100, L40S, GB200/B200 variants, AMD MI300X), and specialized offerings like the OCI Supercluster (designed to scale to many tens of thousands of accelerators with ultralow-latency RDMA networking). OCI highlights very large local storage per node for checkpointing and RDMA networking with microsecond-level latencies. Oracle+1
Nscale: Focused on the latest hyperscaler-class silicon (publicly reported deal to supply NVIDIA GB300 / GB-class chips at scale) and on designing campuses with the power/networking needed to host very high-density GPU racks. Nscale’s value prop is enabling massive, contiguous blocks of the newest accelerators for customers who need scale. nscale.com+1
Takeaway: OCI offers a broad, immediately available catalogue of GPU instances inside a full cloud stack (VMs, bare-metal, networking, storage). Nscale promises extremely large, tightly-engineered deployments of the very latest chips (built around wholesale supply deals) — ideal when you need huge contiguous blocks of identical GPUs.
4) Networking, storage, and cluster capabilities
OCI: Emphasizes ultrafast RDMA cluster networking (very low latency), substantial local NVMe capacity per GPU node for checkpointing and training, and integrated high-performance block/file/object storage for distributed training. OCI’s Supercluster design targets the network and storage patterns of large-scale ML training. Oracle+1
Nscale: As a data-centre builder, Nscale’s engineering focus is on supplying enough power, cooling, and high-bandwidth infrastructure to run dense GPU deployments at hyperscale. Exact publicly-documented RDMA/InfiniBand topology details will depend on the specific deployment/sale (e.g., Microsoft campus). Data Center Dynamics+1
Takeaway: OCI is explicit about turnkey low-latency cluster networking and storage integrated into a full cloud. Nscale provides the raw site-level infrastructure (power, capacity, racks) which customers — or partner hyperscalers — will integrate with their preferred networking and orchestration stacks.
5) Pricing & commercial model
OCI: Typical cloud commercial models (pay-as-you-go VMs, bare-metal by the hour, reserved/committed pricing, enterprise contracts). Oracle often positions OCI GPU VMs/bare metal as price-competitive vs AWS/Azure for GPU workloads and offers enterprise purchasing options. Exact on-demand vs reserved comparisons depend on instance type and region. Oracle+1
Nscale: Business-to-business, large-block commercial contracts (multi-year supply/colocation agreements, reserved capacity). Pricing is negotiated at scale — Nscale’s publicized Microsoft deal is a wholesale/supply/managed capacity arrangement rather than per-hour public cloud list pricing. For organizations that need thousands of GPUs, Nscale will typically offer custom commercial terms. Reuters+1
Takeaway: OCI is priced and packaged for on-demand to enterprise-committed cloud customers; Nscale sells large committed capacity and colocation — better for multi-year, high-volume needs where custom pricing and term structure matter.
6) Ecosystem, integrations & managed services
OCI: Deep integration with Oracle’s enterprise software (databases, Fusion apps), full platform services (Kubernetes, observability, security), and AI developer tooling. OCI customers benefit from a full-stack cloud ecosystem and enterprise SLAs. Oracle
Nscale: Ecosystem strategy centers on partnerships with hyperscalers and OEMs (e.g., Dell involvement in recent deals) and with chip vendors (NVIDIA). Nscale’s role is primarily infrastructure supply; customers will typically integrate their own orchestration and cloud stack or rely on partner hyperscalers for higher-level platform services. nscale.com+1
Takeaway: OCI is a one-stop cloud platform. Nscale is infrastructure-first and will rely on partner ecosystems for platform and application services.
7) Strengths & weaknesses (practical lens)
OCI strengths
Full cloud platform with enterprise services and AI-optimized bare-metal GPUs. Oracle+1
Designed for low-latency distributed training at scale (Supercluster, RDMA). Oracle
Market share and ecosystem mindshare still behind AWS/Azure/GCP in many regions; vendor lock-in concerns for Oracle-centric enterprises.
Nscale strengths
Ability to deliver huge contiguous GPU volumes (100k–200k+ scale) quickly via supply contracts and purpose-built campuses — attractive to hyperscalers and large cloud partners. Recent publicized Microsoft deal is a major signal. Reuters+1
New entrant: rapid growth introduces execution risk (power availability, construction timelines, operational maturity). Big deals depend on multi-year delivery and integration with hyperscaler networks. Financial Times+1
8) Risk & due diligence items
If you’re choosing between them (or evaluating using both), check:
Availability & timeline: OCI instances are available now; Nscale’s large campuses are in active buildout — confirm delivery timelines for GPU blocks you plan to consume. (Nscale’s big deal timelines: deliveries beginning next year in some facilities per press). TechCrunch+1
Network topology & RDMA: If you need low-latency multi-node training, verify the network fabric (OCI documents RDMA / microsecond latencies; for Nscale verify whether customers get InfiniBand/RDMA within the purchased footprint). Oracle+1
Commercial terms: Nscale = custom wholesale/colocation contracts; OCI = public cloud, enterprise agreements and committed-use discounts. Get TCO comparisons for sustained runs. Oracle+1
Operational support & SLAs: OCI provides full cloud SLAs and platform support; Nscale will likely provide data-centre/ops SLAs but may require integration effort depending on the buyer/partner model. Oracle+1
9) Who should pick which?
Pick OCI if you want: Immediate, production-ready cloud with GPU bare-metal/VM options, integrated platform services (K8s, databases, monitoring), and predictable on-demand/reserved pricing — especially if you value managed services and global regions. Oracle+1
Pick Nscale if you want: Multi-thousand to multi-hundred-thousand contiguous GPU capacity under a negotiated multi-year/colocation deal (hyperscaler-scale training, or to supply a cloud product), and you can accept a bespoke onboarding/ops model in exchange for potentially lower per-GPU cost at massive scale. (Recent Microsoft deal signals Nscale’s focus and capability). Reuters+1
Short recommendation & practical next steps
If you’re an enterprise or team needing immediate GPU clusters with full cloud services -> evaluate OCI’s GPU bare-metal and Supercluster options and request price/perf for your model. Use OCI if you want plug-and-play with enterprise services. Oracle+1
If you are planning hyperscale capacity (thousands→100k GPUs) and want to reduce per-GPU cost through long-term committed deployments -> open commercial discussions with Nscale (and other infrastructure suppliers) now; verify delivery schedule, power, networking fabric, and integration model. Reuters+1
Zero-day RCE exploited in the wild. Attackers uploaded malicious PHP code to gain site access.
Summary
Core WordPress is relatively secure today, thanks to fast patching and automatic updates.
Plugins & themes remain the biggest attack surface, especially those with large install bases.
Zero-days in popular plugins (File Manager, WooCommerce, Elementor, etc.) are the most exploited.
Hardening strategies: keep WordPress, themes, and plugins updated; minimize plugin use; use WAF/firewalls; restrict file permissions.
Here are some of the most severe WordPress-related vulnerabilities from roughly the past decade—specifically, those assigned the highest CVSS (Common Vulnerability Scoring System) scores, indicating critical risk:
Top WordPress Vulnerabilities by CVSS Score
1. CVE-2023-5199 – PHP to Page plugin – CVSS 9.9
Type: Authenticated (Subscriber+) Local File Inclusion leading to Remote Code Execution (RCE)
Impact: A subscriber-level user can abuse a shortcode vulnerability to include and execute arbitrary files, potentially enabling full server compromise.
Severity: One of the highest-ever scores for a WordPress plugin. wordfence.com
Impact: Attackers could upload ZIP archives containing PHP backdoors, enabling full site takeover—including admin account creation, malware deployment, phishing redirects, etc.
Note: Exploitation started on July 12, 2025, just two days before public disclosure, affecting approximately 200 live sites. Patched in version 7.8.5 on June 16, 2025. TechRadar
Various plugins – File Inclusions, Privilege Escalation, Auth Bypass
9.8
Data exposure, admin account creation, RCE
CVE-2021-24284
WPBakery Addons – Arbitrary upload → RCE
10.0
Complete site compromise
Recommendations
Plugins & Themes Are the Real Attack Surface Almost all of these high CVSS issues stem from third-party plugins/themes, not WordPress core.
Minimize Risk by Keeping Software Updated Always update plugins/themes immediately when patches are released.
Reduce Attack Surface Use only necessary, well-reviewed plugins and themes. Delete unused ones.
Use Defense-in-Depth Employ Web Application Firewalls (WAF), restrict file permissions, and monitor logs for anomalies.
CVE-2021-24284 – Kaswara Modern WPBakery Page Builder Addons
This vulnerability, rated CVSS 10.0, allowed unauthenticated arbitrary file uploads leading to code execution and full site compromise.
Scope of exposure:
Estimated number of vulnerable sites: Between 4,000 and 8,000 WordPress installations still had the plugin active at the time of reports The Hacker NewsDark Reading.
Sites targeted in attack campaigns: Security researchers observed that approximately 1.6 million websites were scanned in total, though the majority targeted were not actually running the vulnerable plugin BrandefenseSecurity Affairs.
Wordfence noted that over 1,000 websites under their protection were still running the plugin and thus continually targeted The Hacker News.
Unfortunately, no publicly disclosed lists or identities of specific affected websites were available—likely due to privacy and the sensitive nature of security incidents.
Summary:
Estimated vulnerable sites: 4,000–8,000 still installed the plugin.
Total sites scanned in attacks: Around 1.6 million.
Confirmed protected sites running the plugin: Over 1,000, tracked by Wordfence.
CVE-2023-5199 – PHP to Page Plugin
This vulnerability involved a Local File Inclusion (LFI) that could escalate to Remote Code Execution (RCE). It’s less clear which—or how many—websites were actually impacted.
Findings:
I found no publicly available information naming specific affected sites or providing broad estimations of numbers affected.
The known impact stems from the vulnerability leveraged by authenticated users (subscribers or above) using the shortcode—but no data on scale or reported attacks was available from the sources reviewed NVDwiz.io.
Summary Table
CVE ID
Affected Websites / Scope of Impact
Notes
CVE-2021-24284
~4,000–8,000 still had plugin installed; ~1.6 million scanned
No specific site names disclosed; active exploitation observed
CVE-2023-5199
No specific data available on affected sites
No published numbers or site identities
Notes
While industry sources provide a strong sense of scale—thousands of vulnerable sites and millions scanned—they do not reveal actual site names or URLs affected, likely to protect site owners and avoid enabling further attacks.
1. How to Detect if a Site is Vulnerable
Check Plugin/Theme Versions
Look up the affected plugin/theme in the WordPress dashboard under Plugins → Installed Plugins or Appearance → Themes.
Kubernetes already become too unnecessarily complex for enterprise IT?
1. Real-World Data & Surveys: Complexity Is Rising
Spectro Cloud’s 2023 Report shows 75% of Kubernetes practitioners encounter issues running clusters—a significant jump from 66% in 2022. Challenges intensify at scale—especially around provisioning, security, monitoring, and multi-cluster setups. [InfoWorldOkoone]
DEVOPSdigest (2025) highlights that enterprises often run multiple distributions (EKS, GKE, OpenShift), leading to tooling sprawl, operational inconsistency, and fragmented networking/security stacks, which strain platform teams significantly. [devopsdigest.com]
2. Admissions & Simplified Offerings from Google
Google itself acknowledged the persistent complexity of Kubernetes, even after years of improvements—prompting them to offer GKE Autopilot, a managed mode that abstracts away much configuration overhead. [The Register] [Wikipedia]
3. Structural Challenges & Knowledge Gaps
Harpoon’s breakdown of root causes points to:
Kubernetes’ intricate core architecture, multiple components, and high customizability.
Steep learning curve—you need command over containers, infra, networking, storage, CI/CD, automation.
Baytech Consulting (2025) identifies a scaling paradox: what works in pilot can fall apart in enterprise rollouts as complexity, cost, drift, and security fragility compound with growth. [Baytech Consulting]
AltexSoft reports Kubernetes salaries and licensing/infra costs can be high, with unpredictable cloud bills. Around 68% of firms report rising Kubernetes costs, mainly due to over-provisioning and scaling without proper observability. Organizations can waste ~32% of cloud spend. [AltexSoft]
5. Community Voices (Reddit)
Community commentary reflects real frustration:
“One does not simply run a K8s cluster… You need additional observability, cert management, DNS, authentication…”Reddit
“If you think you need Kubernetes, you don’t… Unless you really know what you’re doing.”Reddit
“K8s is f… complex even with EKS. Networking is insane.”Reddit
“Kubernetes stacks are among the most complex I’ve ever dealt with.”Reddit
These quotes show that complexity isn’t just theoretical—it’s a real barrier to adoption and effective operation.
6. Research-Published Failures
A recent academic paper, Mutiny!, reveals that even tiny faults—like single-bit flips in etcd—can cascade into major issues, including cluster-wide failures or under-provisioning. Demonstrates limited fault tolerance unless actively mitigated. [arXiv]
Widespread anecdotes about complexity, overhead, and misapplication
Technical fragility
Experimental research showing failure propagation even from single tiny errors
Powerful with high complexity
Kubernetes is undeniably powerful—but that power comes with a steep complexity tax, especially for enterprises scaling across clusters, clouds, and teams.
Its flexibility and extensibility, while strengths, can also lead to sprawling architectures and tooling sprawl.
Managed services (like GKE Autopilot, EKS, AKS), GitOps, platform engineering teams, and strong governance frameworks are essential to tame this complexity.
For many SMBs or smaller projects, simpler alternatives (Nomad, ECS Fargate, Heroku-style platforms) might be more pragmatic unless you truly need Kubernetes’ scale benefits.
Is Systems Admin in 1990s like managing Kubernetes today?
Systems Administration in the 1990s
In the 1990s, sysadmins typically had to manage on-premises servers, networks, and storage, often with little automation. Key traits:
Heterogeneous environments
Mix of Solaris, HP-UX, AIX, Windows NT, NetWare, early Linux.
Each OS had unique tooling, quirks, and administrative models.
Manual provisioning
Installing from CDs/tapes, hand-editing configs (/etc/*), patching manually.
Network setup via raw config files or proprietary tools.
Siloed tooling
Monitoring with Nagios, Big Brother, MRTG.
Backup with Veritas, Arcserve.
Identity with NIS or LDAP — all separate, poorly integrated.
High skill & resource requirements
A small team of “wizards” needed deep knowledge of Unix internals, networking, SCSI storage, TCP/IP stack quirks, etc.
Troubleshooting required understanding the whole stack, often without Google or Stack Overflow.
Cultural complexity
“Snowflake servers” (no two were alike).
Documentation gaps → single points of knowledge in individuals’ heads.
Vendor support contracts were essential.
Kubernetes Administration Today
Fast forward ~30 years: the “modern sysadmin” (platform/SRE/K8s admin) faces a similar landscape:
Heterogeneous environments
Mix of Kubernetes distros (EKS, GKE, AKS, OpenShift, Rancher).
Add-ons for storage (Rook, Longhorn, CSI drivers), networking (CNI plugins like Calico, Cilium), security (OPA, Kyverno).
Debugging pods across namespaces, RBAC issues, or etcd failures can feel like debugging kernel panics in the 90s.
Cultural complexity
Clusters drift if not well-managed.
“Pets vs. cattle” mindset is the modern equivalent of avoiding snowflake servers.
Knowledge often concentrated in a few “platform engineers.”
Parallels
1990s Sysadmin World
Kubernetes Admin Today
Mix of Unix flavors & Windows NT
Mix of Kubernetes distros (EKS, GKE, AKS, OpenShift)
Manual installs/patching
Manual YAML, Helm, IaC configs
Siloed tools (Nagios, Arcserve, LDAP)
Siloed observability & security stacks
Snowflake servers
Cluster drift, misconfigured CRDs
Need “wizards” with deep system skills
Need platform engineers/SREs with broad skills
Vendor support critical
Reliance on managed services (GKE Autopilot, EKS)
Troubleshooting = art + experience
Debugging multi-layered microservices stacks
Key Difference
Scale & abstraction:
1990s sysadmins often managed tens of servers.
Today’s K8s admins manage hundreds/thousands of pods, spread across multi-cluster, multi-cloud, multi-region environments.
Automation gap:
In the 90s, lack of automation caused complexity.
With Kubernetes, abundance of automation frameworks causes choice overload and integration complexity.
Kubernetes today feels like Unix sysadmin in the 90s:
A powerful but fragmented ecosystem, with high cognitive overhead.
Requires specialists (“K8s wizards”) to keep clusters stable.
Enterprise IT is repeating cycles: adopting bleeding-edge, complex infrastructure that eventually stabilizes into commoditized, simplified platforms (just like Linux standardization simplified 2000s IT).
We’re arguably in the “1995 equivalent” of Kubernetes — powerful but messy. In 5–10 years, we might see a “Linux-like consolidation” or abstraction layer that hides most of today’s complexity.
Timeline Analogy: 1990s Sysadmin vs. Kubernetes Admin Today
1990s: Fragmented Unix + Windows NT Era
Enterprises ran Solaris, HP-UX, AIX, SCO Unix, Novell NetWare, Windows NT, often side by side.
Each had different tooling, package managers, patching mechanisms.
Skills weren’t portable — a Solaris admin couldn’t easily manage NetWare.
Tooling was siloed (Nagios, Arcserve, MRTG, NIS, LDAP, Veritas).
Complexity = every vendor had its own model, and integration was painful.
Analogy to Kubernetes today: Multiple Kubernetes distros (OpenShift, Rancher, GKE, EKS, AKS) + endless CNIs, CSIs, service meshes, observability stacks. Skills don’t fully transfer across environments.
Early 2000s: Linux Standardization & Automation Emerges
Linux (Red Hat, Debian, SUSE) consolidated the Unix ecosystem → standard APIs, packages, and tooling.
Enterprises got more portable skillsets and better ROI from staff.
Analogy for Kubernetes: We’re waiting for similar consolidation in the K8s space — either a dominant “Linux of Kubernetes” (a distro that becomes the de facto enterprise standard) or stronger platform abstractions.
2010s: Cloud + DevOps + Containers
AWS, Azure, GCP commoditized infrastructure.
DevOps culture + automation pipelines became mainstream.
Docker simplified app packaging and delivery.
Enterprises shifted from sysadmin “server caretakers” → SRE/DevOps “platform enablers.”
Analogy for Kubernetes: This was the simplification wave after the complexity of 1990s Unix. Today, K8s is at the “Unix ’95” stage — the complexity is still front and center. The simplification wave (through managed services and PaaS-like abstractions) hasn’t fully happened yet.
2020s: The Future of Kubernetes (Projection)
Managed services (GKE Autopilot, EKS Fargate, AKS) are becoming the equivalent of VMware in the 2000s — hiding underlying infrastructure complexity.
PaaS-like abstractions (Heroku-style experience on top of K8s, e.g., Render, Fly.io, Knative, Crossplane) will likely commoditize Kubernetes itself.
Platform engineering teams will provide “golden paths” to developers, hiding YAML and cluster admin pain.
Just like Linux became invisible (we use it daily without thinking), Kubernetes may fade into the substrate — invisible to developers, only visible to infra specialists.
History Repeats
Era
Sysadmin World
Kubernetes World
Parallel
1990s
Fragmented Unix, NT, manual ops
Fragmented K8s distros, YAML/Helm, manual configs
High complexity, vendor sprawl
2000s
Linux standardizes, automation matures
(Future) K8s consolidates or is abstracted away
Reduced friction, portable skills
2010s
Cloud, DevOps, containers simplify infra
(Future) PaaS & managed services simplify K8s
Devs focus on apps, not infra
2020s
Linux invisible (everywhere, but hidden)
Kubernetes invisible (substrate under platforms)
Only infra teams touch it directly
Summary
Kubernetes today is like Unix in the mid-1990s: powerful but fragmented and resource-intensive. Over the next decade, we’ll likely see Linux-like consolidation (fewer distros, stronger defaults) and/or VMware-like abstraction (managed offerings, PaaS layers) that make Kubernetes complexity mostly invisible to developers.