
Neocloud storage is moving away from “ordinary cloud block volumes attached to GPU VMs” toward AI data-plane engineering: S3-compatible object storage, very fast parallel/shared filesystems, NVMe caching, RDMA fabrics, GPUDirect-style paths, and DPU/SmartNIC offload.
A useful mental model is:
Object storage is becoming the system of record; high-performance file/NVMe tiers feed the GPUs; local NVMe caches smooth bursts; RDMA/DPUs reduce CPU bottlenecks.
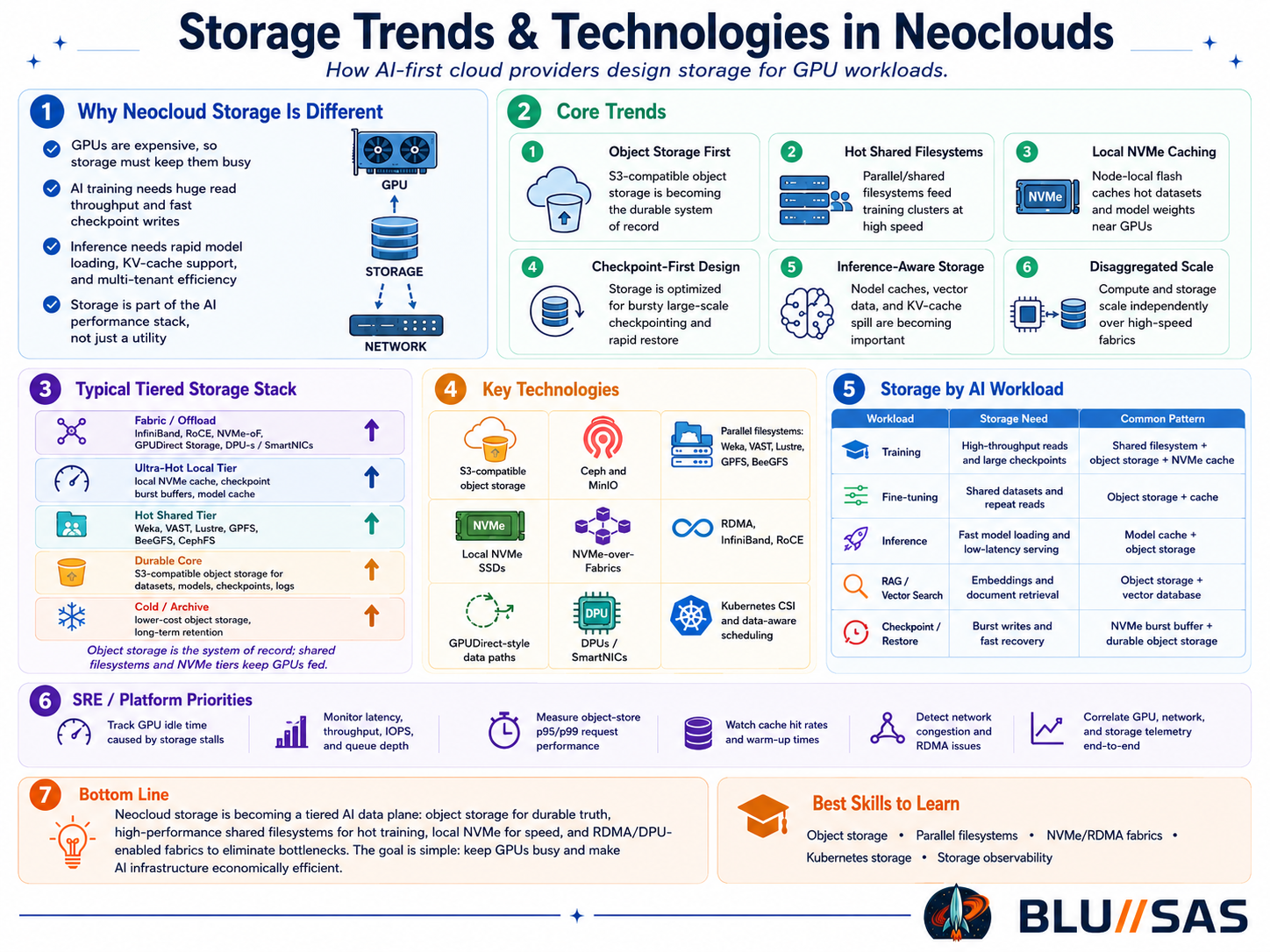
1. Why neocloud storage is different
Neoclouds exist because AI workloads are bottlenecked by more than GPU count. Training and inference clusters need:
| Workload | Storage pressure |
|---|---|
| Dataset loading | Huge sequential reads, many workers, high fan-out |
| Checkpointing | Large concurrent writes without pausing training |
| Fine-tuning | Lots of smaller jobs, shared datasets, repeat reads |
| Inference | Model weight loading, KV cache pressure, vector/RAG data |
| Multi-tenant GPU clouds | Isolation, quotas, predictable noisy-neighbour control |
| Sovereign/private AI clouds | Data locality, encryption, auditability, compliance |
The big shift is that storage is now treated as part of the GPU utilization stack. Bad storage means idle GPUs. Idle GPUs destroy the economics of neoclouds.
2. Object storage is becoming the default data lake
S3-compatible object storage is now central. It is used for datasets, model artefacts, checkpoints, logs, and long-term retention. Crusoe documents S3-compatible object storage for AI/ML workloads, and Nebius offers AI-focused object storage classes including an “Enhanced” class aimed at streaming data to GPUs and checkpointing.
The trend is not “object storage replaces everything.” It is:
Object storage becomes the durable source of truth, while file/NVMe/cache tiers are used to make GPUs fast.
Nebius is a good example of the direction: its Enhanced Object Storage class claims up to 2 GiB/s write throughput per GPU and positions it for GPU streaming and checkpointing. It also claims better latency and throughput versus standard object storage when bucket and client are in the same region.
Why neoclouds like object storage:
| Reason | Why it matters |
|---|---|
| S3 API compatibility | Easy integration with PyTorch, Hugging Face, Spark, Ray, lakehouse tools |
| Scale-out metadata | Better for billions of objects than classic filesystems in some patterns |
| Durability | Better system-of-record semantics |
| Multi-region potential | Important for sovereign and multi-cloud AI |
| Cost tiering | Hot/warm/cold separation becomes easier |
| Tenant isolation | Buckets, IAM, encryption, audit trails |
3. Parallel filesystems remain critical for hot AI workloads
For serious training, POSIX-like shared filesystems are still heavily used: Weka, VAST, DDN EXAScaler/Lustre, IBM Spectrum Scale/GPFS, BeeGFS, DAOS, and sometimes CephFS. These matter because many AI pipelines still expect filesystem semantics, fast directory traversal, shared mounts, and high concurrent read/write throughput.
CoreWeave publicly describes its storage as AI-focused and says it uses managed storage services with partners including VAST Data and WEKA. VAST also announced a major commercial partnership with CoreWeave, with Reuters reporting a $1.17 billion agreement for VAST to become a main data platform supporting CoreWeave’s GPU-powered cloud services.
This is the clearest signal: neoclouds are not treating storage as a commodity sidecar. They are signing huge strategic storage deals because storage is part of the AI factory.
Common hot-tier technologies:
| Technology | Typical role |
|---|---|
| VAST Data | High-performance NFS/S3-ish unified AI data platform |
| WEKA | High-performance parallel filesystem for GPU workloads |
| DDN EXAScaler / Lustre | HPC-style parallel filesystem, common in supercomputing |
| IBM Spectrum Scale / GPFS | Enterprise/HPC parallel filesystem |
| BeeGFS | HPC parallel filesystem, often simpler to deploy than Lustre |
| DAOS | Object-oriented HPC storage, strong RDMA/NVMe direction |
| Ceph / CephFS / RADOSGW | Open-source block/file/object, popular where cost/control matter |
The split is usually:
| Tier | Storage |
|---|---|
| Ultra-hot | Local NVMe on GPU nodes |
| Hot shared | Weka/VAST/DDN/Lustre/GPFS/BeeGFS |
| Durable system of record | S3-compatible object storage |
| Cold/archive | Lower-cost object storage, tape, external cloud, erasure-coded pools |
4. Local NVMe cache is becoming a major design pattern
A major trend is object storage plus local NVMe acceleration. Instead of forcing every GPU worker to read repeatedly from a remote shared filesystem, neoclouds cache datasets, model weights, and shards on local NVMe near the GPU.
SemiAnalysis described this emerging pattern as S3-compatible object storage paired with large distributed local NVMe caches, citing CoreWeave’s LOTA as an example.
Why this matters:
| Without local cache | With local NVMe cache |
|---|---|
| Repeated remote reads hammer shared storage | Hot data stays close to GPUs |
| GPU nodes wait on network/storage | GPU utilization improves |
| Object store latency hurts training | Cache hides latency |
| Checkpoints overload central storage | Burst writes can be staged/absorbed |
| Scaling storage requires huge back-end spend | Cache distributes load across GPU fleet |
This is one of the most important neocloud differentiators. Hyperscalers already built decades of object/file/cache layers. Neoclouds are now building AI-specific versions faster and with less legacy.
5. Checkpointing has become a first-class storage problem
Large model training produces enormous checkpoints. A checkpoint storm can saturate storage, networks, metadata servers, and object-store request paths.
Modern neocloud storage has to support:
| Requirement | Why |
|---|---|
| High parallel write bandwidth | Thousands of GPUs checkpoint together |
| Low training interruption | Checkpointing must not stall expensive GPU jobs |
| Async/staged checkpointing | Write locally first, flush later |
| Incremental/delta checkpoints | Reduce write volume |
| Fast restore | Failed training jobs must resume quickly |
| Cross-region replication | Disaster recovery and customer portability |
This is why high-performance object storage and parallel filesystems are both used. Object storage is durable and scalable; the hot filesystem/NVMe tier absorbs the burst.
6. RDMA, InfiniBand and RoCE are storage technologies now
In AI clusters, networking and storage are merging. Storage traffic increasingly runs over high-performance fabrics: NVIDIA Quantum InfiniBand, Spectrum-X Ethernet, RoCE, NVMe-over-Fabrics, and RDMA-aware object/file stacks.
The reason is simple: GPUs consume data at extreme rates. TCP/IP and CPU-mediated I/O paths become expensive.
Emerging direction:
| Layer | Trend |
|---|---|
| Network | InfiniBand, RoCE, Spectrum-X Ethernet |
| Storage protocol | NVMe-oF, RDMA object/file access |
| Data movement | GPUDirect Storage-style paths |
| Offload | BlueField DPU / SmartNIC |
| Security | Inline encryption, tenant isolation, confidential computing |
NVIDIA’s 2026 BlueField-4 STX announcement is a good example of where this is heading: storage architecture built around DPUs, ConnectX networking, RDMA, NVMe SSDs, and KV-cache/agentic-AI pressure. Reports say cloud providers including CoreWeave, Lambda, and Oracle Cloud Infrastructure are early adopters, with STX systems expected in the second half of 2026.
7. KV cache and inference storage are now separate concerns
Training storage is mostly about datasets and checkpoints. Inference storage is increasingly about:
| Inference pressure | Storage impact |
|---|---|
| Huge model weights | Fast model loading and warm pools |
| Long context windows | KV cache can exceed GPU memory |
| Multi-tenant serving | Fast model swap and isolation |
| RAG | Vector DBs, document stores, embeddings |
| Agentic workflows | More intermediate state and context persistence |
This means storage for neoclouds is no longer just “feed training jobs.” It is also serve inference economically.
Long-context inference creates a new tiering problem:
| Tier | Used for |
|---|---|
| HBM | Active tokens, attention state |
| GPU memory pools | Hot model execution |
| Host RAM | Overflow and staging |
| Local NVMe | KV cache spill, model cache |
| Object storage | Model artefacts, datasets, logs |
That is why DPU/NVMe/KV-cache work matters. It is not academic; it directly affects token throughput and cost per million tokens.
8. Storage-compute disaggregation is increasing
Classic HPC often had tightly coupled storage appliances near compute. Neoclouds increasingly want disaggregated storage:
| Disaggregated model | Benefit |
|---|---|
| Compute scales independently | Add GPUs without duplicating storage |
| Storage scales independently | Add capacity/bandwidth separately |
| Better fleet utilization | Avoid stranded disks or stranded GPUs |
| Easier multi-tenancy | Central policy, quotas, billing |
| Better lifecycle management | Different refresh cycles for GPU and storage hardware |
But disaggregation only works if the network is excellent. Otherwise, you simply move the bottleneck from disk to fabric.
This is why AI neoclouds pair storage disaggregation with RDMA, high-radix fabrics, telemetry, and placement-aware scheduling.
9. Open-source storage still matters, but the top end often buys commercial
For a neocloud, storage choices usually split by market segment.
| Use case | Likely storage choice |
|---|---|
| Cost-sensitive GPU cloud | Ceph, MinIO, JuiceFS, BeeGFS |
| Sovereign/private cloud | Ceph, MinIO, NetApp, VAST, WEKA |
| Large training clusters | VAST, WEKA, DDN, Lustre, GPFS |
| Kubernetes-native AI platform | S3 + CSI volumes + cache + object gateways |
| HPC/AI hybrid | Lustre, GPFS, BeeGFS, DAOS |
| Inference platform | Object storage + local NVMe model cache + vector DB |
Ceph is attractive because it gives block, file, and object in one open platform. MinIO is attractive for S3-compatible object storage. But for very large GPU clusters, commercial platforms often win because the cost of underutilized GPUs dwarfs storage licensing costs.
10. Kubernetes is shaping storage interfaces
Most neoclouds expose GPU infrastructure through Kubernetes or Kubernetes-like orchestration. That affects storage architecture.
Important pieces:
| Kubernetes storage component | Role |
|---|---|
| CSI drivers | Attach block/file volumes |
| Object bucket claims / operators | Provision S3 buckets |
| Local PersistentVolumes | Use node NVMe |
| Topology-aware scheduling | Place pods near data/cache |
| RDMA device plugins | Expose high-performance fabric |
| Data preload jobs | Stage datasets before GPU jobs |
| Checkpoint controllers | Manage checkpoint lifecycle |
| Kubeflow/Ray/Slurm integration | AI job orchestration |
The future pattern is likely not “one filesystem mounted everywhere.” It is workflow-aware storage orchestration: datasets staged, caches warmed, checkpoints flushed, model artefacts versioned, and GPU jobs scheduled based on both compute and data locality.
11. Observability for storage is becoming essential
For SREs, the storage layer needs deep telemetry. Neoclouds must know whether a training job is slow because of GPU, network, storage, framework, or tenant interference.
Metrics that matter:
| Area | Metrics |
|---|---|
| GPU impact | GPU idle time due to input stalls |
| Filesystem | metadata ops/sec, read/write latency, throughput, queue depth |
| Object storage | request rate, 4xx/5xx, p99 latency, multipart throughput |
| NVMe | wear, temperature, IOPS, bandwidth, latency, queue depth |
| Network | RDMA retransmits, congestion, ECN, PFC pause frames |
| Checkpointing | checkpoint duration, failure rate, restore time |
| Cache | hit ratio, eviction rate, warm-up time |
| Tenant fairness | noisy neighbour detection, quota pressure |
For an SRE, the winning skill is correlating GPU utilization + network fabric + storage latency + application checkpoint/data-loader behaviour.
12. Likely direction over the next 2–3 years
The strongest trends are:
- S3-compatible object storage becomes the durable AI data substrate.
- High-performance POSIX filesystems remain critical for hot training paths.
- Local NVMe cache becomes standard on GPU nodes.
- RDMA/NVMe-oF/GPUDirect/DPU offload moves into mainstream AI storage.
- Checkpointing becomes a product feature, not an afterthought.
- Inference storage becomes as important as training storage because of model caches, KV caches, RAG, and long context windows.
- Storage scheduling becomes integrated with Kubernetes, Slurm, Ray, and AI platform layers.
- Commercial AI storage vendors keep winning at the high end because GPU idle time is too expensive.
- Open-source stacks like Ceph, MinIO, BeeGFS, DAOS, and JuiceFS remain important for sovereign, private, and cost-controlled neoclouds.
- Storage observability becomes a differentiator for SRE/platform teams.
Bottom line
Neocloud storage is becoming a tiered AI data plane:
Cold / durable:
S3-compatible object storage, erasure coding, replication, lifecycle policies
Warm / shared:
High-performance object storage, lakehouse data, model artefacts
Hot / training:
VAST, WEKA, DDN/Lustre, GPFS, BeeGFS, DAOS, CephFS
Ultra-hot / node-local:
NVMe cache, staged datasets, checkpoint burst buffers, model cache
Fabric/offload:
InfiniBand, RoCE, NVMe-oF, GPUDirect Storage, BlueField DPUs, SmartNICsFor SRE/platform engineering, the practical takeaway is: learn object storage deeply, learn parallel filesystems, understand NVMe/RDMA fabrics, and build observability that proves whether GPUs are waiting on storage.
What neoclouds need from storage
For neoclouds, storage has to solve several hard problems at once:
| Requirement | Why it matters |
|---|---|
| Very high read throughput | Training jobs need to feed thousands of GPUs continuously |
| Fast checkpoint writes | Large model checkpoints can create synchronized write storms |
| Low metadata overhead | AI datasets can contain millions or billions of files/objects |
| S3 + POSIX access | AI pipelines use object APIs, filesystems, containers, notebooks, and distributed jobs |
| Multi-tenancy | GPU cloud customers need isolation, quotas, billing, and policy control |
| Data locality and caching | Model weights and datasets need to be close to compute |
| RDMA / GPUDirect / NVMe paths | CPU-mediated I/O can become the bottleneck |
| Operational observability | SREs need to prove whether GPUs are idle because of storage, network, or application issues |
That is why neocloud storage is usually a tiered AI data plane rather than one generic SAN/NAS array.
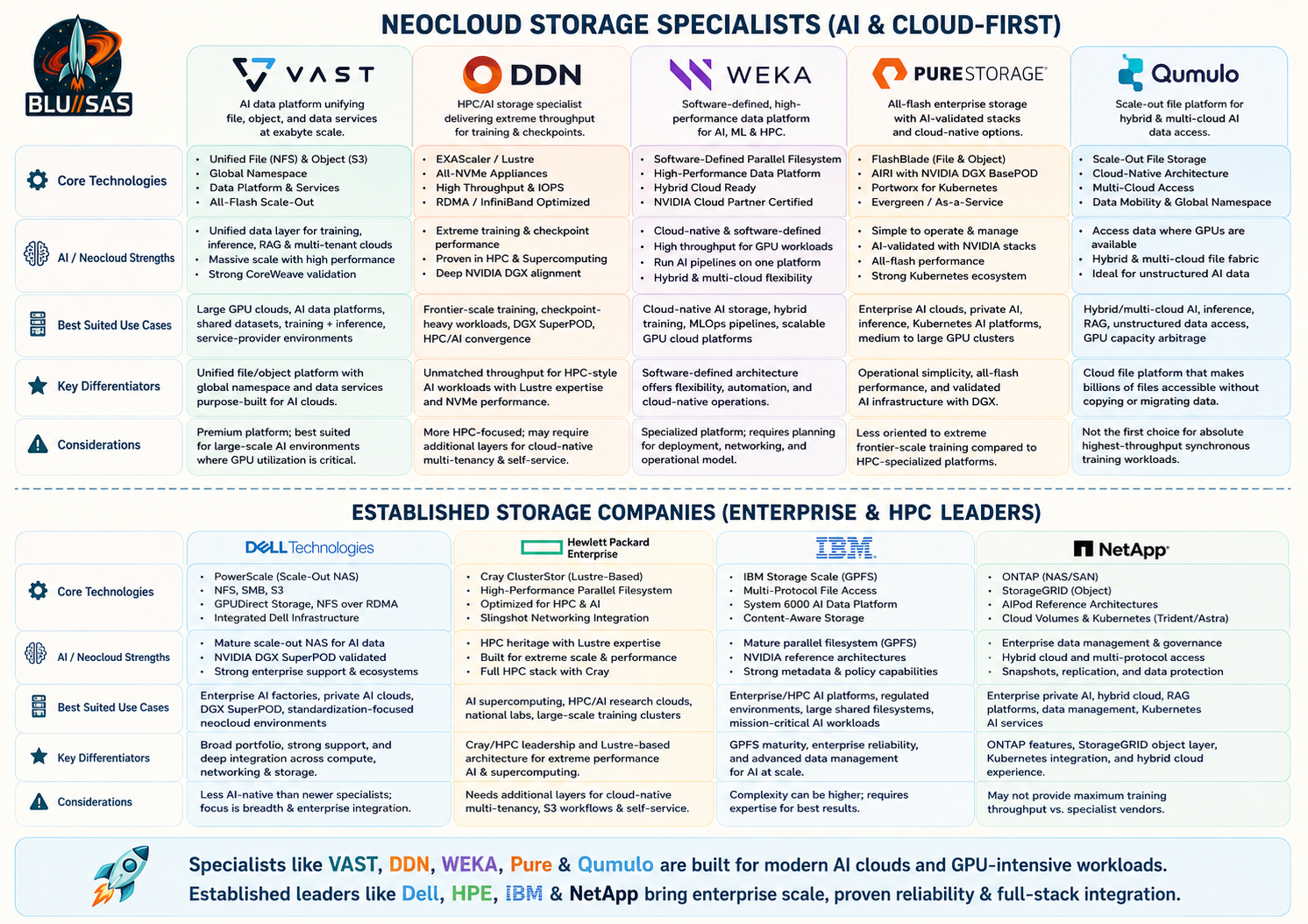
1. VAST Data
What VAST is
VAST Data is one of the most visible AI-era storage companies. It positions itself not merely as storage, but as a broader AI data platform combining storage, database-like services, global namespace, and data services. Its architecture is heavily aimed at exabyte-scale unstructured data, AI training/inference pipelines, GPU clouds, and large shared datasets.
VAST has strong neocloud credibility because CoreWeave uses VAST as a major data platform; Reuters reported a $1.17 billion VAST-CoreWeave commercial agreement, with VAST supporting CoreWeave’s GPU-powered cloud services for training and running AI models.
Relevant technologies
VAST’s platform is especially relevant to neoclouds because it tries to collapse several separate storage roles into one platform:
| Area | VAST approach |
|---|---|
| File storage | High-performance NFS-style shared access |
| Object storage | S3-compatible access for AI data lakes and cloud-native workflows |
| Namespace | Global namespace for distributed datasets |
| Data services | Data platform features beyond basic storage |
| AI use case | Shared data layer for training, inference, RAG, and multi-tenant GPU clouds |
VAST explicitly markets its platform for AI clouds and service providers, saying its platform consolidates storage, database, and global namespace capabilities for service-provider productization.
Why it suits neoclouds
VAST is attractive when a neocloud wants:
- A single high-performance unstructured data platform rather than separate NAS, object store, metadata store, and data-service islands.
- A platform that can support both training and inference data flows.
- Multi-tenant AI cloud storage with service-provider features.
- Global-scale datasets, data sharing, and data mobility.
Strengths
| Strength | Why it matters |
|---|---|
| Strong AI-cloud market fit | Built around large-scale AI data rather than generic enterprise NAS alone |
| Unified file/object story | Useful because AI workflows often mix POSIX and S3 |
| Strong CoreWeave validation | Neocloud adoption is a major signal |
| Global namespace / data platform direction | Useful for distributed GPU clouds |
| All-flash performance orientation | Good for hot AI datasets |
Watch-outs
VAST is powerful but not necessarily the cheapest or simplest. It is best suited to large-scale AI environments where GPU economics justify premium storage. For small clusters or cost-sensitive internal platforms, Ceph, MinIO, BeeGFS, or simpler NAS/object storage may be more appropriate.
Neocloud fit
Very strong fit for GPU cloud providers, AI factories, large-scale model training, RAG platforms, and shared AI data services.
2. DDN
What DDN is
DDN is a long-standing HPC and AI storage specialist. It is deeply associated with supercomputing, Lustre, parallel filesystems, large research systems, national labs, and NVIDIA DGX-oriented AI infrastructure.
For neoclouds, DDN is important because it represents the HPC-derived high-performance storage path: extreme throughput, parallel file access, fast checkpointing, and close alignment with GPU supercomputing.
Relevant technologies
DDN’s AI portfolio includes systems such as the AI400X2 Turbo and its EXAScaler/Lustre-based AI storage platforms. DDN states that the AI400X2 Turbo can deliver up to 115 GB/s read, 75 GB/s write, and 3 million IOPS for large AI workloads.
DDN has also described previous AI400X2 systems delivering more than 90 GB/s and 3 million IOPS to an NVIDIA DGX A100 system, with all-NVMe usable capacity options.
Why it suits neoclouds
DDN fits neoclouds that look more like GPU supercomputers as a service than conventional cloud file services.
| Use case | DDN suitability |
|---|---|
| Large model training | Very strong |
| Checkpoint-heavy workloads | Very strong |
| HPC + AI convergence | Very strong |
| DGX SuperPOD / BasePOD style clusters | Strong |
| Research AI clusters | Strong |
| Generic enterprise file sharing | Less differentiated |
Strengths
| Strength | Why it matters |
|---|---|
| HPC heritage | Mature for large parallel workloads |
| Lustre / EXAScaler expertise | Well suited to training and checkpointing |
| NVIDIA AI infrastructure alignment | Important for DGX-style deployments |
| Very high throughput appliances | Directly addresses GPU starvation |
| Proven in supercomputing | Good for national-lab and research-scale environments |
Watch-outs
DDN can feel more like HPC infrastructure than cloud-native storage. For neoclouds serving many different customers, additional layers may be needed for S3 abstraction, self-service provisioning, tenant controls, Kubernetes integration, and cloud-style billing.
Neocloud fit
Excellent fit for the hot training tier, checkpoint tier, and HPC/AI supercomputing-style neoclouds.
3. WEKA
What WEKA is
WEKA is a software-defined, high-performance data platform aimed at AI, ML, HPC, and cloud-native data-intensive workloads. Unlike DDN’s stronger appliance/HPC feel, WEKA is often positioned as a more cloud-like, software-defined parallel filesystem/data platform.
WEKA says its AI/ML platform can run the entire AI data pipeline on one platform, on-premises or in public cloud, and can combine multiple sources into a single high-performance computing system.
WEKA also states that its Data Platform is certified as a high-performance data-store solution for NVIDIA Cloud Partners, supporting large-scale AI deployments with high throughput and scalability.
Relevant technologies
| Area | WEKA approach |
|---|---|
| Core architecture | Distributed, software-defined high-performance filesystem |
| Deployment | On-prem, cloud, hybrid |
| AI use case | Training, inference, data pipelines, HPC/AI convergence |
| GPU cloud angle | NVIDIA Cloud Partner certification |
| Data access | High-performance file access, cloud integration, tiering patterns |
Reuters reported that WEKA raised $140 million in a Series E round in 2024 at a $1.6 billion valuation, with participation from NVIDIA and Qualcomm Ventures, and described WEKA as providing high-performance and scalable file storage for data-intensive applications.
Why it suits neoclouds
WEKA is particularly interesting for neoclouds because it is:
- Software-defined, which suits cloud-style automation.
- Strong on parallel file performance.
- Designed for hybrid cloud and cloud-native data workflows.
- Less tied to one hardware appliance model than some traditional storage systems.
- Attractive where a neocloud wants high performance but also elasticity and automation.
Strengths
| Strength | Why it matters |
|---|---|
| Software-defined architecture | Easier to automate and integrate with cloud platforms |
| Strong AI/HPC performance story | Good for feeding GPUs |
| Hybrid/on-prem/cloud positioning | Useful for neoclouds spanning sites |
| NVIDIA Cloud Partner certification | Strong signal for GPU-cloud relevance |
| Pipeline-oriented messaging | Useful for MLOps and AI data workflows |
Watch-outs
WEKA is still a specialized platform. Teams need to understand its deployment, networking, failure domains, tiering, and cost model. It is not simply a drop-in replacement for an enterprise NAS if the workload is generic office file sharing.
Neocloud fit
Very strong fit for cloud-native AI storage, training clusters, hybrid AI infrastructure, and service-provider GPU clouds.
4. Pure Storage
What Pure is
Pure Storage is a major all-flash enterprise storage company. For neoclouds, the relevant products are less about traditional block storage and more about FlashBlade, AIRI, and AI-ready data platforms.
Pure describes FlashBlade as a scale-out platform for both file and object storage, intended for unstructured data.
Pure also markets AIRI as a pre-certified NVIDIA DGX BasePOD stack using FlashBlade, aimed at accelerating enterprise AI deployment and improving GPU utilization.
Relevant technologies
| Area | Pure approach |
|---|---|
| File/object storage | FlashBlade |
| AI integrated stack | AIRI with NVIDIA DGX BasePOD |
| Enterprise consumption | Evergreen / as-a-service style models |
| Kubernetes | Portworx for cloud-native storage |
| Enterprise AI | Validated AI infrastructure rather than pure HPC |
Why it suits neoclouds
Pure is attractive where the neocloud or private AI cloud wants:
- Enterprise-grade all-flash storage.
- Strong supportability and lifecycle management.
- Unified file/object for AI datasets.
- Validated NVIDIA AI infrastructure.
- Kubernetes storage through Portworx.
- Simpler operations than more HPC-centric stacks.
Strengths
| Strength | Why it matters |
|---|---|
| Operational simplicity | Pure is known for manageability |
| All-flash performance | Good for AI hot data |
| FlashBlade file/object | Useful for unstructured AI datasets |
| AIRI / NVIDIA validation | Useful for enterprise AI stacks |
| Portworx | Stronger Kubernetes story than many array vendors |
| Evergreen model | Attractive for lifecycle management |
Watch-outs
Pure’s sweet spot is often enterprise AI infrastructure rather than the very largest hyperscale/neocloud training fabrics. It can absolutely support AI workloads, but at very large neocloud scale, vendors like VAST, WEKA, and DDN may be more directly associated with GPU cloud hot-path storage.
Neocloud fit
Strong fit for enterprise neoclouds, private AI clouds, AI inference platforms, Kubernetes AI platforms, and medium-to-large GPU clusters.
5. Qumulo
What Qumulo is
Qumulo is a scale-out file storage company focused on unstructured data, cloud file storage, and hybrid/multi-cloud data access. It is not traditionally as HPC-heavy as DDN or as AI-cloud famous as VAST, but it has an increasingly relevant story for AI data mobility.
Qumulo says its Data Platform helps make billions of files accessible to AI workflows on-premises or in cloud, without copying or migrating data, and supports running AI workloads wherever compute is available across AWS, Azure, GCP, OCI, or on-premises.
Relevant technologies
| Area | Qumulo approach |
|---|---|
| Core platform | Scale-out file storage |
| Cloud model | Cloud-native and hybrid file services |
| Data mobility | Access data where GPU compute exists |
| AI/ML use case | Training, inference, GPU workflows |
| Differentiator | Multi-cloud file fabric / cloud file access |
Qumulo also markets high-performance cloud file storage for demanding cloud-based workflows.
Why it suits neoclouds
Qumulo is most interesting when the problem is:
“My data is in one place, but GPU capacity is somewhere else.”
That is an increasingly common neocloud problem. GPU liquidity means customers may want to run jobs wherever GPUs are available, but data gravity makes that hard.
Strengths
| Strength | Why it matters |
|---|---|
| Strong cloud file story | Useful for hybrid and multi-cloud AI |
| Unstructured-data focus | AI datasets are often unstructured |
| Data mobility positioning | Good for GPU capacity arbitrage |
| Simpler than HPC Lustre-style systems | Easier for enterprise teams |
| Cloud deployment options | Useful for burst and hybrid workflows |
Watch-outs
Qumulo is generally less associated with the absolute highest-end model-training hot path than DDN, VAST, or WEKA. For large synchronous training jobs, you would need to validate throughput, metadata, GPU utilization, and checkpoint behavior carefully.
Neocloud fit
Good fit for hybrid AI, cloud file services, inference/RAG data access, and enterprise AI workflows. Less obviously the first choice for the largest frontier-model training tier.
Specialist comparison: VAST vs DDN vs WEKA vs Pure vs Qumulo
| Vendor | Best described as | Strongest neocloud role |
|---|---|---|
| VAST | AI data platform / unified file-object-global namespace | Large GPU clouds, shared AI data platform, training + inference |
| DDN | HPC/AI parallel storage specialist | Extreme training throughput, checkpoints, DGX/SuperPOD-style systems |
| WEKA | Software-defined high-performance AI filesystem/data platform | Cloud-native AI storage, hybrid training, scalable GPU clouds |
| Pure | Enterprise all-flash file/object + AI integrated stacks | Enterprise AI clouds, private AI, Kubernetes AI, validated DGX stacks |
| Qumulo | Scale-out cloud file platform | Hybrid/multi-cloud AI data access, unstructured AI data, GPU liquidity |
Simplified ranking by neocloud use case
| Use case | Strongest candidates |
|---|---|
| Frontier-scale training | DDN, VAST, WEKA |
| GPU cloud shared data platform | VAST, WEKA |
| DGX/SuperPOD-style HPC AI | DDN, IBM, Dell, Pure, NetApp depending on architecture |
| Enterprise private AI cloud | Pure, NetApp, Dell, IBM, VAST, WEKA |
| Kubernetes-heavy AI platform | Pure/Portworx, WEKA, NetApp, Dell, VAST |
| Hybrid/multi-cloud file access | Qumulo, NetApp, WEKA, VAST |
| RAG / inference data serving | VAST, Pure, Qumulo, NetApp, WEKA |
| Open HPC-style AI | DDN/Lustre, HPE ClusterStor, IBM Storage Scale |
Now compare with standard storage companies
6. Dell Technologies
What Dell offers
Dell has one of the broadest enterprise infrastructure portfolios: servers, networking, storage, data protection, and AI reference architectures. For AI/neocloud storage, the most relevant product is usually PowerScale, Dell’s scale-out NAS platform based on the Isilon lineage.
Dell has a PowerScale reference architecture for NVIDIA DGX SuperPOD aimed at high-performance scale-out AI enterprise environments.
Dell also says PowerScale introduced GPUDirect Storage and NFS over RDMA capabilities in earlier AI work, and that the PowerScale F710 became the first Ethernet-based storage certified for NVIDIA DGX SuperPOD.
Strengths
| Strength | Why it matters |
|---|---|
| Broad enterprise footprint | Many customers already buy Dell infrastructure |
| PowerScale maturity | Proven scale-out NAS |
| NVIDIA AI Factory alignment | Easier procurement for enterprise AI |
| End-to-end stack | Servers, storage, networking, services |
| Good for enterprise standardization | Procurement and support are straightforward |
Weaknesses versus specialists
Dell can be very strong for enterprise AI, but it may feel less AI-native than VAST or WEKA and less HPC-specialized than DDN. Its advantage is breadth, support, and integration; its disadvantage is that neoclouds may want more specialized storage economics, performance models, or cloud-native multi-tenant features.
Neocloud fit
Strong for enterprise AI factories and private AI clouds. For a pure-play neocloud, Dell can be part of the stack, but the hot AI storage layer may still be evaluated against VAST, WEKA, DDN, or Pure.
7. HPE
What HPE offers
HPE’s strongest AI/HPC storage story comes from the Cray acquisition and the Cray ClusterStor line. ClusterStor E1000 embeds the open-source Lustre parallel filesystem and is designed for HPC-style performance.
That makes HPE very relevant where neoclouds look like AI supercomputers, especially when paired with HPE Cray compute, Slingshot networking, and HPC operating models.
Strengths
| Strength | Why it matters |
|---|---|
| Cray/HPC heritage | Very strong for supercomputing-style AI |
| Lustre-based architecture | Well understood in HPC training/checkpoint workloads |
| Large-scale systems expertise | Suitable for national-lab and research-scale AI |
| Full HPC stack | Compute, networking, storage, services |
| Enterprise support for open HPC tech | Easier than self-supporting Lustre |
Weaknesses versus specialists
HPE ClusterStor is excellent for HPC-style AI, but it is not necessarily the easiest platform for a cloud-native multi-tenant neocloud. It may need additional layers for S3 workflows, self-service storage provisioning, Kubernetes-native integration, billing, and customer isolation.
Neocloud fit
Strong for AI supercomputing and HPC-AI clouds. Less obviously ideal for a general-purpose GPU neocloud where customers expect cloud-native object/file abstractions and rapid self-service.
8. IBM
What IBM offers
IBM’s key product is IBM Storage Scale, formerly GPFS. This is one of the most mature parallel filesystems in the world and is heavily used in HPC, research, analytics, and enterprise high-performance data environments.
IBM positions Storage Scale with NVIDIA as an integrated solution for enterprise AI applications at scale, and IBM lists reference architectures for NVIDIA HGX, GB200/GB300 NVL72, DGX BasePOD, and DGX SuperPOD.
IBM also describes the Storage Scale System 6000 AI Data Platform as delivering massive throughput with integrated GPU acceleration and content-aware storage.
Strengths
| Strength | Why it matters |
|---|---|
| GPFS / Storage Scale maturity | Very strong for parallel file workloads |
| Enterprise and HPC credibility | Works in serious regulated and research environments |
| NVIDIA reference architectures | Relevant to GPU clusters |
| Multi-protocol and data-management features | Useful in enterprise AI |
| Strong metadata and policy capabilities | Important for large datasets |
Weaknesses versus specialists
IBM Storage Scale is powerful but can be complex. It may require deep skills to operate well. Compared with VAST or WEKA, it can feel more traditional/HPC-enterprise than AI-cloud-native. Compared with DDN, it is less specifically a turnkey Lustre appliance model.
Neocloud fit
Strong for enterprise/HPC AI platforms, regulated AI environments, and large shared filesystems. Good fit where operational maturity exists.
9. NetApp
What NetApp offers
NetApp is a major enterprise storage incumbent with ONTAP, AFF, StorageGRID, Cloud Volumes, Astra/Trident, and AI reference architectures. For AI, NetApp markets AIPod reference architectures and high-performance storage platforms for AI/ML workloads.
NetApp’s strength is not only performance; it is also enterprise data management: snapshots, replication, tiering, governance, cloud integration, and mature NAS/SAN operations.
Strengths
| Strength | Why it matters |
|---|---|
| Enterprise NAS maturity | Many organizations already trust NetApp |
| ONTAP features | Snapshots, replication, policy, multiprotocol access |
| Strong hybrid-cloud story | Good for enterprise AI data mobility |
| Kubernetes integration | Trident/Astra ecosystem |
| AIPod architectures | Validated AI stack approach |
| StorageGRID object storage | Useful for object/data-lake layer |
Weaknesses versus specialists
NetApp is strong in enterprise AI, but for pure GPU-cloud hot-path storage it may face tough competition from VAST, WEKA, DDN, and Pure. Its strongest argument is enterprise integration and governance rather than being the most AI-native scale-out training filesystem.
Neocloud fit
Strong for enterprise private AI, regulated environments, hybrid cloud, RAG, and data management. Less clearly the first choice for maximum-throughput frontier-model training.
Specialist vendors vs traditional vendors
High-level comparison
| Dimension | VAST / DDN / WEKA / Pure / Qumulo | Dell / HPE / IBM / NetApp |
|---|---|---|
| Market posture | AI-forward or specialist storage | Broad enterprise/HPC incumbents |
| Neocloud messaging | Stronger for VAST, WEKA, DDN; growing for Pure/Qumulo | Strong but often under “AI factory” or enterprise AI |
| Procurement | More specialized | Easier for enterprise standardization |
| Operations | Can be highly specialized | More familiar to enterprise infra teams |
| Performance focus | Often optimized for GPU data paths | Varies: very strong in HPC products, broader in enterprise portfolios |
| Cloud-native fit | WEKA, VAST, Qumulo, Pure/Portworx strong | NetApp/Dell/Pure strong enterprise Kubernetes stories; HPE/IBM more HPC-enterprise |
| Multi-tenancy | Stronger in AI-cloud platforms, but varies | Often needs enterprise/cloud management wrappers |
| Best use | AI factories, GPU clouds, hot training tiers | Enterprise AI, HPC systems, validated infrastructure, regulated environments |
The main architectural difference
The specialist vendors tend to start from this problem:
“How do we feed and protect GPU workloads at massive scale?”
The incumbents often start from this problem:
“How do we extend proven enterprise/HPC storage into AI infrastructure?”
Both are valid. The right answer depends on whether the neocloud is optimizing for maximum GPU utilization, enterprise governance, cost, cloud-native operations, or HPC-style throughput.
Where each company fits in a neocloud architecture
Durable object layer
| Best candidates |
|---|
| VAST, Pure FlashBlade, NetApp StorageGRID, Dell object options, MinIO/Ceph alternatives, Qumulo where file-first access dominates |
For a neocloud, object storage is usually the system of record for datasets, model artefacts, logs, and checkpoints.
Hot training filesystem
| Best candidates |
|---|
| DDN, WEKA, VAST, IBM Storage Scale, HPE ClusterStor, Dell PowerScale, Pure FlashBlade, NetApp AFF/AIPod depending on workload |
This is the tier that decides whether GPUs sit idle.
Checkpoint tier
| Best candidates |
|---|
| DDN, WEKA, VAST, HPE ClusterStor, IBM Storage Scale, Dell PowerScale, Pure FlashBlade |
Checkpointing is especially hard because many workers write at once. You want high write bandwidth, good metadata behavior, and fast restore.
Inference/model-serving tier
| Best candidates |
|---|
| VAST, Pure, Qumulo, NetApp, WEKA, Dell PowerScale |
Inference storage is increasingly about model-weight caching, RAG/vector data, document stores, and KV-cache spill/adjacent storage.
Hybrid/multi-cloud AI data fabric
| Best candidates |
|---|
| Qumulo, NetApp, WEKA, VAST, Pure, Dell |
This matters when GPU capacity is distributed and customers want to run workloads wherever GPUs are available.
Practical decision matrix
| Scenario | Best short-list |
|---|---|
| Building a CoreWeave-style GPU neocloud | VAST, WEKA, DDN |
| Building a DGX SuperPOD-style training cluster | DDN, IBM Storage Scale, Dell PowerScale, Pure, NetApp, HPE ClusterStor |
| Building an HPC/AI research cloud | DDN, HPE ClusterStor, IBM Storage Scale, WEKA, VAST |
| Building an enterprise private AI cloud | Pure, NetApp, Dell, IBM, VAST |
| Building cloud-native Kubernetes AI services | WEKA, Pure/Portworx, NetApp/Trident, VAST, Qumulo |
| Building hybrid AI data access across public clouds | Qumulo, NetApp, WEKA, VAST |
| Cost-controlled internal GPU platform | Ceph, MinIO, BeeGFS, plus selected commercial tier if needed |
| Maximum raw checkpoint/training performance | DDN, WEKA, VAST, HPE ClusterStor, IBM Storage Scale |
SRE/platform engineering view
For an SRE, the important thing is not the logo on the array. It is whether the storage platform exposes the right primitives and telemetry.
What to evaluate in a proof of concept
| Area | What to test |
|---|---|
| GPU utilization | Does storage keep GPUs above target utilization? |
| Read throughput | Can it sustain distributed dataloader reads? |
| Write throughput | Can it handle synchronized checkpoints? |
| Metadata | Does performance collapse with millions/billions of files? |
| Small files | Can it handle image/text/token shards efficiently? |
| Object API | Does S3 behavior work with ML tooling? |
| POSIX semantics | Does NFS/POSIX behavior match frameworks? |
| Failure recovery | What happens during node, disk, controller, or network loss? |
| Multi-tenancy | Quotas, isolation, noisy-neighbour handling |
| Kubernetes integration | CSI, topology awareness, dynamic provisioning |
| Observability | Prometheus metrics, logs, tracing, audit events |
| Network behavior | RDMA errors, ECN/PFC, retransmits, queue depth |
| Cost model | Cost per usable TB, cost per GB/s, cost per GPU kept busy |
Metrics you should demand
| Metric category | Examples |
|---|---|
| GPU correlation | GPU idle time due to input stalls |
| Filesystem | p95/p99 latency, throughput, metadata ops/sec |
| Object storage | S3 request rate, p95/p99 latency, multipart failures |
| Checkpoints | checkpoint duration, restore time, failure rate |
| Cache | hit ratio, eviction rate, warm-up time |
| NVMe | wear, queue depth, bandwidth, latency |
| RDMA/network | congestion, retransmits, packet drops, PFC pause frames |
| Tenant fairness | per-tenant throughput, throttling, noisy-neighbour impact |
Bottom line
For neoclouds, I would group the vendors like this:
| Category | Vendors | Interpretation |
|---|---|---|
| AI-cloud specialists | VAST, WEKA | Strongest “modern AI data platform” positioning |
| HPC/AI performance specialists | DDN, HPE ClusterStor, IBM Storage Scale | Strongest for supercomputer-like training and checkpointing |
| Enterprise AI all-flash platforms | Pure, Dell, NetApp | Strong for private AI, validated stacks, enterprise operations |
| Hybrid/cloud file specialists | Qumulo, NetApp, WEKA | Strong where data mobility and multi-cloud GPU access matter |
| Broad incumbents | Dell, HPE, IBM, NetApp | Strongest when enterprise support, procurement, and full-stack integration matter |
My practical shortlist would be:
- VAST if building a large AI-cloud data platform.
- DDN if the priority is maximum training/checkpoint performance with HPC-style operations.
- WEKA if you want software-defined, high-performance AI storage with cloud-like flexibility.
- Pure if you want enterprise AI simplicity, all-flash file/object, and Kubernetes/Portworx options.
- Qumulo if the key challenge is hybrid/multi-cloud file access and moving AI workloads to wherever GPU capacity exists.
- Dell / HPE / IBM / NetApp if you need enterprise procurement, validated reference architectures, broad support, and integration with existing infrastructure standards.

For neocloud storage, the open-source products are mostly used in four layers:
| Layer | Open-source products |
|---|---|
| Object storage / S3 layer | Ceph RGW, MinIO |
| Parallel training filesystem | Lustre, BeeGFS, DAOS |
| Cloud-native POSIX-over-object layer | JuiceFS |
| Kubernetes persistent storage | Longhorn, OpenEBS, Rook-Ceph |
The main difference versus VAST, DDN, WEKA, Pure, Qumulo, Dell, HPE, IBM, and NetApp is that open-source storage usually gives you control, flexibility, and cost leverage, but you take on more integration, tuning, operational risk, and support responsibility.
1. Ceph
Ceph is the broadest open-source storage platform in this list. It provides object, block, and file storage from one distributed cluster built on commodity hardware. The core storage layer is RADOS; on top of that you typically use RADOS Gateway for S3-compatible object storage, RBD for block volumes, and CephFS for POSIX-style shared file storage. The Ceph project describes it as an open-source distributed storage system providing unified object, block, and file services.
Where it fits in a neocloud
Ceph is attractive as a general-purpose storage substrate for neoclouds and private AI clouds:
| Ceph interface | Neocloud use |
|---|---|
| RGW / S3 | Dataset buckets, model artefacts, checkpoint archive, logs |
| RBD | VM volumes, Kubernetes PersistentVolumes, control-plane storage |
| CephFS | Shared filesystems for tools, notebooks, pipelines, moderate AI jobs |
| Rook-Ceph | Kubernetes-native Ceph deployment and management |
Likely consumers
Ceph is likely to be used by:
| Consumer | Why they would use Ceph |
|---|---|
| Cost-sensitive neoclouds | Avoid proprietary array/platform costs |
| Sovereign/private cloud operators | Full control over hardware, data locality, encryption, operations |
| OpenStack clouds | Ceph is a common backend for Cinder, Glance, Nova ephemeral disks, and object storage |
| Kubernetes platform teams | Rook-Ceph gives block, file, and object in-cluster |
| Universities/research clouds | Commodity hardware + open platform fits constrained budgets |
| MSPs and regional clouds | They can build S3/block/file services without hyperscaler dependency |
Pros
| Pro | Why it matters |
|---|---|
| Unified block/file/object | One storage platform can support many cloud primitives |
| Commodity hardware | Good for cost control and sovereignty |
| Mature ecosystem | Widely deployed in OpenStack, Kubernetes, and private cloud |
| S3-compatible object via RGW | Useful for AI datasets and model artefacts |
| Strong failure-domain controls | CRUSH maps allow rack/host/device-aware placement |
| Erasure coding | Useful for capacity-efficient object/archive tiers |
| Rook integration | Strong Kubernetes deployment model |
Cons
| Con | Why it matters |
|---|---|
| Operational complexity | Ceph rewards expertise; poor design causes pain |
| Performance tuning burden | Network, OSD layout, BlueStore, DB/WAL, replication, EC pools all matter |
| Not automatically a high-end AI filesystem | CephFS is useful, but not usually the first choice for extreme GPU training hot paths |
| Hardware-sensitive | Mixed disks, weak networks, or poor failure domains cause instability |
| Upgrades require discipline | Large clusters need careful version, PG, and recovery management |
| Metadata-heavy workloads can hurt | Billions of tiny files or hot directory patterns need careful design |
Neocloud verdict
Ceph is excellent for the durable storage core of a private/neocloud platform: object, block, VM volumes, Kubernetes PVs, and archive. It is less likely to be the absolute fastest hot training filesystem compared with DDN/Lustre, WEKA, VAST, or BeeGFS.
2. MinIO
MinIO is an S3-compatible object store focused on performance, simplicity, and cloud-native deployment. The MinIO GitHub project describes it as a high-performance S3-compatible object storage solution released under the GNU AGPL v3.0 licence, designed for AI/ML, analytics, and data-intensive workloads.
Where it fits in a neocloud
MinIO fits the object storage / AI data lake layer:
| Use | MinIO fit |
|---|---|
| Model artefact storage | Strong |
| Dataset buckets | Strong |
| Checkpoint archive | Strong |
| Loki/Mimir/Tempo-style object backend | Strong |
| Kubernetes-native S3 service | Strong |
| POSIX shared training filesystem | Not its role |
Likely consumers
| Consumer | Why |
|---|---|
| Kubernetes platform teams | Easy to deploy as S3-compatible object storage |
| AI/ML platform teams | Familiar S3 API for datasets and artefacts |
| Smaller neoclouds | Simpler than building full Ceph object initially |
| SaaS/platform teams | Embedded object storage for internal services |
| Labs and homelabs | Lightweight way to learn S3-style infrastructure |
| Edge/private AI deployments | Compact S3 layer close to compute |
Pros
| Pro | Why it matters |
|---|---|
| S3 API focus | Works with common ML, data, backup, and observability tools |
| Operational simplicity | Easier mental model than full Ceph |
| Kubernetes-friendly | Common in Helm/operator-based deployments |
| High-performance object store | Good for object-native AI pipelines |
| Good developer experience | mc client, simple bucket model, familiar S3 semantics |
| Useful for observability stacks | Common backend for Loki, Mimir, Tempo, Thanos-style systems |
Cons
| Con | Why it matters |
|---|---|
| Object only | No native block or POSIX filesystem role |
| AGPL considerations | Commercial/service-provider use needs legal review and possibly subscription planning |
| Not a parallel filesystem | Training code expecting POSIX/NFS/Lustre semantics needs another layer |
| Metadata/object pattern matters | Lots of tiny objects or poor multipart usage can become inefficient |
| Multi-tenant cloud service design is on you | IAM, quotas, chargeback, isolation, and lifecycle policy need careful platform work |
| Enterprise support may be required | For production neocloud use, support/subscription questions matter |
Neocloud verdict
MinIO is a strong choice for the S3-compatible data lake/system-of-record tier, especially in Kubernetes and private AI environments. Pair it with a hot filesystem or NVMe cache layer for GPU training.
3. Lustre
Lustre is the classic open-source parallel filesystem for HPC. The Lustre project describes it as an open-source parallel filesystem for leadership-class HPC simulation environments. OpenSFS describes Lustre as POSIX-compliant, scalable to thousands of clients, hundreds of petabytes, and several TB/s of sustained I/O bandwidth, with broad use in major supercomputing sites.
Where it fits in a neocloud
Lustre belongs in the hot training / checkpoint tier:
| Use | Lustre fit |
|---|---|
| Large distributed training reads | Very strong |
| Checkpoint-heavy workloads | Very strong |
| HPC + AI clusters | Very strong |
| Scratch filesystem | Very strong |
| Long-term object archive | Not its primary role |
| Cloud-style S3 service | Needs additional layer |
Likely consumers
| Consumer | Why |
|---|---|
| HPC centres | Existing Lustre skills and workflows |
| National labs and universities | Proven at large scale |
| AI research clusters | High-throughput POSIX filesystem for training |
| Neoclouds with HPC DNA | Good fit for GPU supercomputing-as-a-service |
| Weather, simulation, genomics, physics groups | Traditional parallel I/O workloads |
| DDN/HPE-style deployments | Commercial Lustre appliances often wrap open Lustre |
Pros
| Pro | Why it matters |
|---|---|
| Extreme parallel throughput | Feeds many GPU/CPU clients |
| Mature HPC ecosystem | Known by schedulers, MPI users, HPC admins |
| POSIX/global namespace | Works with legacy scientific/AI workflows |
| Strong for large sequential I/O | Good for sharded datasets and checkpoints |
| Commercial support ecosystem | DDN, HPE, Whamcloud/OpenSFS ecosystem |
| Proven at supercomputer scale | Important for trust in extreme workloads |
Cons
| Con | Why it matters |
|---|---|
| Operationally specialized | Requires Lustre/HPC storage expertise |
| Not cloud-native by default | Self-service, quotas, S3, Kubernetes integration need extra work |
| Metadata bottlenecks possible | Small-file workloads need careful MDT design |
| Failure handling requires expertise | OST/MDT recovery, networking, failover need discipline |
| Tenant isolation is not automatic | Neocloud multi-tenancy needs wrapping layers |
| Less natural for object-native data lakes | Often paired with S3/object storage rather than replacing it |
Neocloud verdict
Lustre is one of the strongest open-source choices for maximum hot-tier AI training and checkpoint performance, especially where the neocloud behaves like an HPC GPU supercomputer.
4. BeeGFS
BeeGFS is another parallel cluster filesystem designed for performance and ease of deployment. Its GitHub README describes it as a parallel cluster filesystem focused on performance and designed for easy installation and management. BeeGFS markets itself for large-scale HPC and AI clusters.
One important caveat: the current BeeGFS licensing model has evolved. BeeGFS says its Community licence allows use as a high-performance scratch filesystem, access to source code, and internal modification, while defining boundaries for fair use. So it is “source-available/open community” in practice, but you should review the licence carefully for commercial neocloud service-provider use.
Where it fits in a neocloud
| Use | BeeGFS fit |
|---|---|
| AI scratch filesystem | Strong |
| HPC/AI shared filesystem | Strong |
| GPU cluster shared training data | Strong |
| Easier parallel FS deployment than Lustre | Often a strength |
| Object storage system of record | Not its main role |
| Enterprise multi-tenant cloud storage | Needs platform wrapping |
Likely consumers
| Consumer | Why |
|---|---|
| Universities and research labs | Performance without full Lustre complexity |
| Smaller HPC/AI clusters | Easier to deploy and operate |
| AI teams needing scratch/shared POSIX | Good practical shared filesystem |
| Sovereign AI clouds | More control over stack |
| Platform teams prototyping AI hot tiers | Faster path than complex HPC appliances |
| Specialist MSPs | Can build custom high-performance storage services |
Pros
| Pro | Why it matters |
|---|---|
| Easier than Lustre for many teams | Lower operational entry barrier |
| Good performance for HPC/AI | Suitable hot shared tier |
| Flexible hardware choices | Can run on commodity servers/NVMe |
| Good for scratch workloads | Matches many training/intermediate-data patterns |
| Familiar POSIX-style access | Easy for users and frameworks |
| Good fit for medium-scale clusters | Strong balance of performance and manageability |
Cons
| Con | Why it matters |
|---|---|
| Licence/commercial-use review needed | Important for neoclouds selling services |
| Smaller ecosystem than Lustre | Fewer very-large reference architectures |
| Not object-native | Needs S3/object tier alongside it |
| Needs tuning | Network, metadata, chunking, client config matter |
| Multi-tenancy is not turnkey | Quotas, customer isolation, chargeback need extra layers |
| Less vendor gravity than DDN/VAST/WEKA | May be harder to get enterprise confidence |
Neocloud verdict
BeeGFS is attractive for medium-to-large AI/HPC scratch and shared file tiers, especially where Lustre feels too heavy and commercial platforms are too expensive.
5. DAOS
DAOS, Distributed Asynchronous Object Storage, is an open-source software-defined high-performance storage system for AI and HPC workloads. The DAOS project describes it as an open-source platform for AI and HPC. Its GitHub repository describes DAOS as an open-source software-defined object store designed for massively distributed non-volatile memory, licensed under BSD-2-Clause Plus Patent License.
Where it fits in a neocloud
DAOS is best seen as a next-generation HPC/AI object storage layer, not as ordinary S3 object storage.
| Use | DAOS fit |
|---|---|
| Extreme HPC/AI I/O | Strong |
| NVMe-heavy storage pools | Strong |
| Scientific workflows | Strong |
| Object-native high-performance workloads | Strong |
| POSIX compatibility via FUSE | Possible, but not the core ideal |
| Simple S3-compatible cloud storage | Not the obvious choice |
Likely consumers
| Consumer | Why |
|---|---|
| Exascale/HPC centres | Designed for high-performance object I/O |
| National labs | Strong fit for scientific computing |
| Weather/simulation/analytics platforms | Can suit high-throughput structured I/O |
| Advanced AI research infrastructure | Interesting for metadata-heavy/high-performance data paths |
| Storage R&D teams | Architecture is advanced and worth evaluating |
| Cloud providers with deep storage engineering | Can build differentiated services, but needs skill |
Pros
| Pro | Why it matters |
|---|---|
| Designed for high-performance object I/O | Avoids some traditional POSIX bottlenecks |
| NVMe/NVM-oriented architecture | Good match for modern flash-heavy clusters |
| Open governance direction via DAOS Foundation | Better long-term ecosystem prospects |
| Multiple access interfaces | Native APIs, POSIX/FUSE-style compatibility options |
| Strong HPC/AI ambition | Relevant to future AI storage designs |
| Potentially excellent metadata behavior | Important for complex scientific/AI workloads |
Cons
| Con | Why it matters |
|---|---|
| More specialized and less mainstream | Harder hiring/support than Ceph or Lustre |
| Application model matters | Best performance may require DAOS-aware software |
| Not a generic enterprise NAS/S3 replacement | Needs careful workload matching |
| Operational maturity varies by environment | Requires skilled engineering |
| Smaller ecosystem | Fewer off-the-shelf integrations than S3/POSIX stacks |
| Migration path may be harder | Existing apps usually expect POSIX, S3, or NFS |
Neocloud verdict
DAOS is interesting for advanced HPC/AI storage engineering, but it is less likely to be the first generic storage choice for a commercial neocloud unless the team has deep HPC/storage expertise.
6. JuiceFS
JuiceFS is an open-source distributed POSIX filesystem built on object storage plus a separate metadata engine. Its documentation describes it as an open-source, high-performance distributed filesystem under Apache 2.0, providing full POSIX compatibility and allowing object storage to be mounted like a massive local disk across hosts, platforms, and regions. JuiceFS stores file data in object storage and metadata separately in engines such as Redis, PostgreSQL, MySQL, or similar systems.
Where it fits in a neocloud
JuiceFS is a bridge between object storage and POSIX workflows.
| Use | JuiceFS fit |
|---|---|
| POSIX access over S3/object storage | Strong |
| Cloud-native shared filesystem | Strong |
| Hybrid/multi-cloud data access | Strong |
| ML datasets stored in object storage | Strong |
| Extreme hot training filesystem | Depends heavily on cache, metadata, and workload |
| Replacement for Lustre at frontier scale | Usually not the first assumption |
Likely consumers
| Consumer | Why |
|---|---|
| AI platform teams using S3 | Gives POSIX mounts over object storage |
| Kubernetes-heavy teams | Can mount shared data into pods |
| Hybrid cloud users | Object backend can be cloud or private S3 |
| Data science teams | Familiar file semantics over object data |
| Cost-sensitive private AI clouds | Avoids premium commercial filesystem |
| Platform teams needing simple global data access | Useful abstraction layer |
Pros
| Pro | Why it matters |
|---|---|
| POSIX over object storage | Useful where apps are not object-native |
| Cloud-native architecture | Good fit for Kubernetes and hybrid cloud |
| Apache 2.0 licence | Easier for commercial use than copyleft/open-core concerns |
| Works with many object stores | S3, MinIO, Ceph RGW, public cloud object stores |
| Separate metadata layer | Can be fast if metadata engine is designed well |
| Good for multi-cloud data workflows | Object storage backend gives portability |
Cons
| Con | Why it matters |
|---|---|
| Metadata engine becomes critical | Redis/Postgres/MySQL/TiKV availability and performance matter |
| FUSE overhead | May not match kernel-native/parallel FS performance in hot paths |
| Cache design is essential | Without local cache, object latency hurts |
| Consistency and semantics need validation | POSIX-over-object is not identical to local filesystem behavior under all workloads |
| Not automatically suitable for checkpoint storms | Needs testing under real AI write patterns |
| Adds another moving part | Object store + metadata DB + clients + cache |
Neocloud verdict
JuiceFS is a very useful cloud-native POSIX compatibility layer over object storage, especially for AI platforms that already use S3/MinIO/Ceph. It is not automatically a replacement for DDN/Lustre/WEKA/VAST in the hottest training tier.
7. Longhorn
Longhorn is a CNCF-incubating distributed block storage system for Kubernetes. The Longhorn project describes it as cloud-native distributed block storage built using Kubernetes and container primitives. The project website says Longhorn provides simplified, 100% open-source persistent block storage with snapshots and backups.
Where it fits in a neocloud
Longhorn is for Kubernetes PersistentVolumes, not for feeding thousands of GPUs with training data.
| Use | Longhorn fit |
|---|---|
| Kubernetes app volumes | Strong |
| Stateful services | Strong |
| Small databases, control-plane tools, dashboards | Strong/moderate |
| Edge Kubernetes storage | Strong |
| AI training dataset hot tier | Weak |
| Massive shared filesystem | Not its role |
Likely consumers
| Consumer | Why |
|---|---|
| Kubernetes platform teams | Easy persistent volumes |
| Homelabs and small private clouds | Simple UI and snapshots |
| Edge AI clusters | Lightweight distributed block storage |
| Internal developer platforms | Good default storage class |
| Observability/control-plane stacks | Grafana, small DBs, app storage |
| Rancher/SUSE users | Strong ecosystem fit |
Pros
| Pro | Why it matters |
|---|---|
| Very Kubernetes-native | Works naturally with CSI and PVs |
| Easy to deploy | Low barrier compared with Ceph |
| UI, snapshots, backups | Operationally friendly |
| Good for small/medium clusters | Practical default block storage |
| Runs on local node disks | Useful for commodity Kubernetes |
| CNCF project | Community and ecosystem visibility |
Cons
| Con | Why it matters |
|---|---|
| Block storage only | Not object or shared file storage |
| Not a high-performance AI hot tier | Wrong tool for large distributed training reads |
| Replica traffic can be expensive | Network overhead matters |
| Performance depends heavily on disks/network | NVMe and 25/100GbE matter if pushing it |
| Large-scale operations need care | Rebuilds, snapshots, backups, and node failures can hurt |
| Not ideal for very write-heavy DBs without validation | Test before production-critical use |
Neocloud verdict
Longhorn is good for Kubernetes platform services and persistent volumes, not for neocloud AI data-plane storage. Use it for Grafana, metadata services, control-plane apps, small databases, or edge workloads—not the main GPU training filesystem.
8. OpenEBS
OpenEBS is an open-source Kubernetes-native storage platform. OpenEBS says it turns storage available on Kubernetes worker nodes into local or distributed PersistentVolumes. Its documentation describes OpenEBS as enabling dynamic local or replicated container-attached Kubernetes PersistentVolumes, and notes it is a leading choice for NVMe-based deployments.
Where it fits in a neocloud
OpenEBS is a Kubernetes PV/storage-class framework:
| Use | OpenEBS fit |
|---|---|
| LocalPV for fast node-local storage | Strong |
| NVMe-backed Kubernetes workloads | Strong |
| Replicated PVs | Strong depending on engine |
| Control-plane/stateful app storage | Strong |
| Main AI object store | Not its role |
| Parallel training filesystem | Not its role |
Likely consumers
| Consumer | Why |
|---|---|
| Kubernetes SRE/platform teams | Declarative PV management |
| AI platform teams needing local NVMe PVs | Useful for cache, scratch, model staging |
| Edge/private Kubernetes operators | Lightweight and flexible |
| Teams wanting local-first performance | LocalPV can be very fast |
| Developers running stateful workloads | Simple Kubernetes-native pattern |
| Cost-sensitive clusters | Uses existing node disks |
Pros
| Pro | Why it matters |
|---|---|
| Kubernetes-native | Managed through familiar APIs and storage classes |
| Strong LocalPV story | Excellent for NVMe local cache/scratch |
| Flexible engines | Local and replicated options |
| Good for AI cache tiers | Node-local NVMe can be exposed cleanly |
| Lightweight compared with Ceph | Easier to reason about for some use cases |
| Works well with declarative GitOps | Good platform engineering fit |
Cons
| Con | Why it matters |
|---|---|
| Not a shared AI filesystem | It provides PVs, not a Lustre/WEKA/VAST equivalent |
| LocalPV ties workloads to nodes | Scheduling and failure handling become important |
| Replication adds overhead | Network and rebuild cost matter |
| Operational model varies by engine | Need to choose LocalPV vs replicated engines carefully |
| Not an object store | Needs MinIO/Ceph/etc. for S3 |
| Not enough alone for neocloud storage | It is one layer, not the whole data plane |
Neocloud verdict
OpenEBS is excellent for Kubernetes-local NVMe storage, scratch, cache, and application PVs. It complements object stores and parallel filesystems rather than replacing them.
Product-by-product summary
| Product | Type | Best neocloud role | Most likely consumers |
|---|---|---|---|
| Ceph | Distributed block/file/object | Durable core: S3, block, CephFS, OpenStack/K8s backend | OpenStack clouds, sovereign clouds, universities, MSPs |
| MinIO | S3-compatible object store | AI object store / data lake / model artefacts | K8s teams, AI platforms, smaller neoclouds |
| Lustre | Parallel POSIX filesystem | Hot training and checkpoint filesystem | HPC centres, AI supercomputing clouds, research labs |
| BeeGFS | Parallel cluster filesystem | AI/HPC scratch and shared file tier | Medium HPC/AI clusters, labs, sovereign AI |
| DAOS | High-performance object store for HPC/AI | Advanced HPC/AI object I/O tier | Exascale/HPC centres, national labs, deep storage teams |
| JuiceFS | POSIX filesystem over object storage | Cloud-native POSIX-over-S3 layer | AI platform teams, hybrid cloud, K8s teams |
| Longhorn | Kubernetes distributed block storage | Kubernetes PVs for apps/control plane | K8s operators, edge clusters, homelabs |
| OpenEBS | Kubernetes local/replicated PV storage | Local NVMe cache/scratch and PVs | K8s SREs, AI platform teams, edge/private clouds |
Which consumers are most likely to choose open source?
1. Regional and sovereign neoclouds
They care about data locality, independence from hyperscalers, and cost control. They are likely to combine:
Ceph RGW or MinIO -> object storage
Ceph RBD -> VM/block volumes
Lustre/BeeGFS -> hot AI training filesystem
OpenEBS/Longhorn -> Kubernetes PVsTheir main challenge is staffing: they need SREs who understand Linux storage, networking, failure domains, Kubernetes, and observability.
2. Universities, research institutes, and HPC centres
They are likely to use:
Lustre / BeeGFS / DAOS -> HPC/AI filesystem or object layer
Ceph / MinIO -> object/data archive
Slurm -> scheduler
Kubernetes -> newer AI/platform layerThey often have the right culture for open source: deep systems expertise, slower procurement, and strong need for customisation.
3. Enterprise private AI platforms
They may use open source selectively:
MinIO -> S3-compatible internal object store
Rook-Ceph -> Kubernetes/OpenStack backend
Longhorn/OpenEBS -> developer platform PVs
JuiceFS -> POSIX over object for AI teamsLarge enterprises may still prefer Pure, NetApp, Dell, IBM, or HPE for production-critical support, but open source often appears in platform engineering and internal AI labs.
4. Cost-sensitive AI startups
They may choose:
MinIO + JuiceFS + local NVMe
or
Ceph + Kubernetes CSI
or
BeeGFS for scratchThey want to avoid large upfront storage contracts, but the risk is that storage failures can consume engineering time and hurt GPU utilization.
5. Homelab and learning environments
For learning neocloud storage, the best sequence is:
1. MinIO
2. Longhorn or OpenEBS
3. Rook-Ceph
4. JuiceFS over MinIO/Ceph
5. BeeGFS
6. Lustre
7. DAOSThat sequence moves from cloud-native and approachable toward HPC-specialist.
Open source versus commercial specialist storage
| Dimension | Open source | Commercial specialist platforms |
|---|---|---|
| CapEx/licensing | Lower licence cost | Higher licence/subscription cost |
| Control | Very high | Vendor-controlled roadmap/support |
| Hardware choice | Flexible | Sometimes certified hardware only |
| Operational burden | Higher | Lower if vendor support is strong |
| Time to production | Longer | Usually faster |
| Performance ceiling | Can be excellent | Often easier to reach reliably |
| Support | Community/self/vendor optional | Enterprise support included/expected |
| Multi-tenancy | You build/integrate | Often stronger product features |
| Observability | You assemble/export | Often more integrated |
| Best fit | Skilled teams, sovereign clouds, research, cost control | GPU clouds where idle GPU cost dwarfs storage cost |
Practical architecture patterns
Pattern A: Open-source private/neocloud core
Object/system of record: Ceph RGW or MinIO
Block volumes: Ceph RBD
Shared file: CephFS or JuiceFS
Hot AI scratch: BeeGFS or Lustre
Kubernetes PVs: Rook-Ceph, OpenEBS, or Longhorn
Local NVMe cache: OpenEBS LocalPV or node-local PVsBest for: regional clouds, sovereign AI platforms, research clouds, cost-sensitive private AI.
Pattern B: HPC-first AI cloud
Hot training filesystem: Lustre or BeeGFS
Experimental object tier: DAOS
Durable object archive: Ceph RGW or MinIO
Scheduler: Slurm
Kubernetes layer: Separate platform for services/inferenceBest for: GPU supercomputing, research, scientific AI, training-heavy clusters.
Pattern C: Kubernetes-first AI platform
Object store: MinIO or Ceph RGW
POSIX over object: JuiceFS
Kubernetes PVs: Longhorn / OpenEBS / Rook-Ceph
Local cache: OpenEBS LocalPV / node NVMe
GPU orchestration: Kubernetes + Volcano/Kueue/Ray/KubeflowBest for: MLOps, fine-tuning platforms, inference, RAG, internal AI platforms.
My practical recommendations
For a neocloud or AI platform, I would not pick one open-source storage product and expect it to do everything.
Sensible shortlist by layer
| Layer | Best open-source candidates |
|---|---|
| S3/object system of record | MinIO, Ceph RGW |
| OpenStack/private cloud storage | Ceph |
| Kubernetes PVs | Rook-Ceph, Longhorn, OpenEBS |
| POSIX over object storage | JuiceFS |
| Hot AI scratch/shared filesystem | Lustre, BeeGFS |
| Advanced HPC/AI object storage | DAOS |
| Local NVMe cache | OpenEBS LocalPV, Kubernetes Local PVs |
Best default combinations
For a small AI platform:
MinIO + OpenEBS/Longhorn + local NVMeFor a serious private cloud:
Ceph + Rook-Ceph + MinIO or Ceph RGW + OpenEBS LocalPVFor a training-heavy GPU cluster:
Lustre or BeeGFS + MinIO/Ceph object archive + local NVMe cacheFor an advanced HPC/AI lab:
Lustre/BeeGFS + DAOS evaluation + Ceph/MinIO object tierThe cleanest SRE takeaway is:
Use object storage for durable truth, parallel filesystems for GPU training throughput, Kubernetes PV systems for platform services, and local NVMe for cache/scratch. Do not force one open-source storage system to solve every neocloud storage problem.